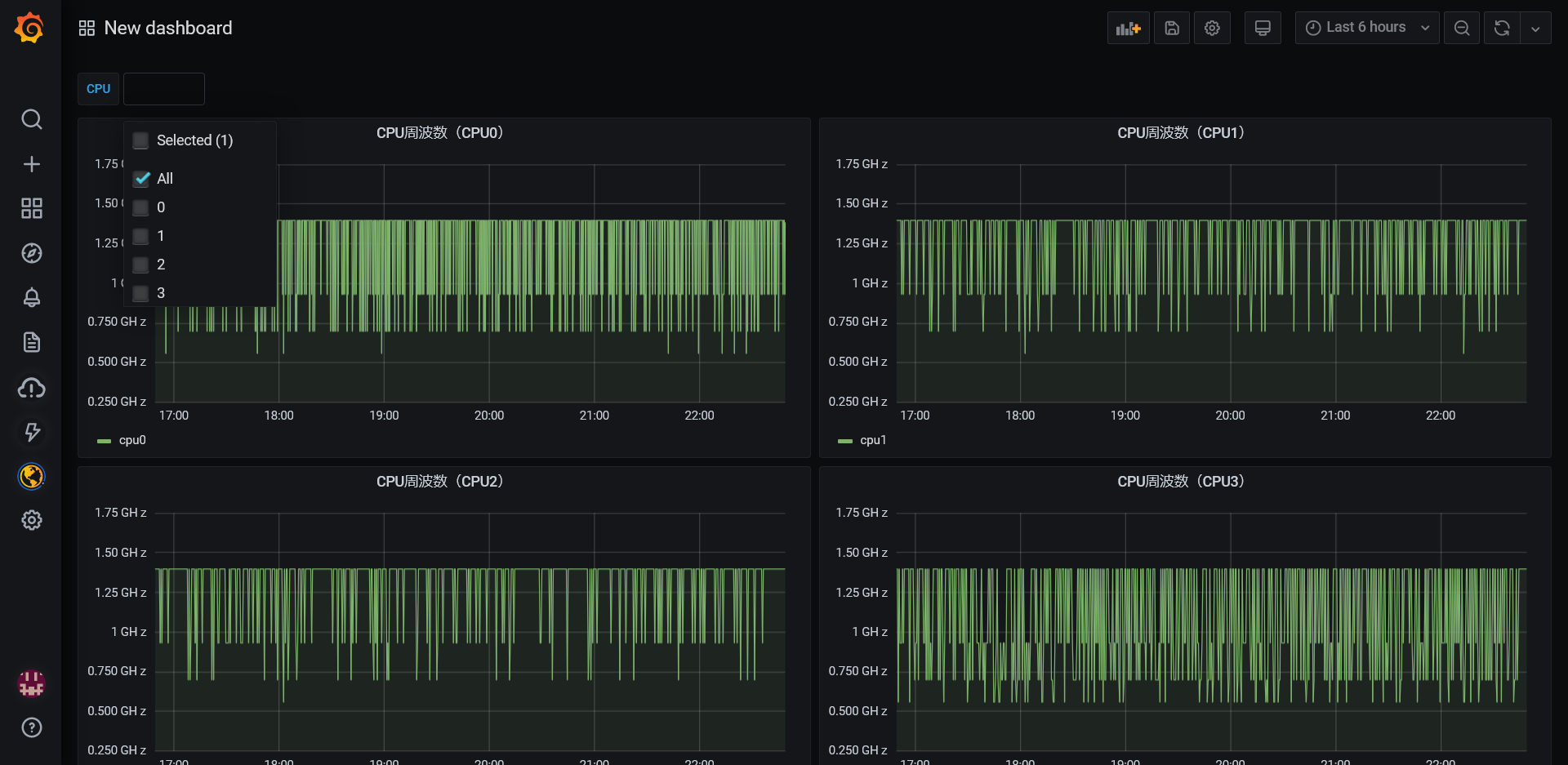
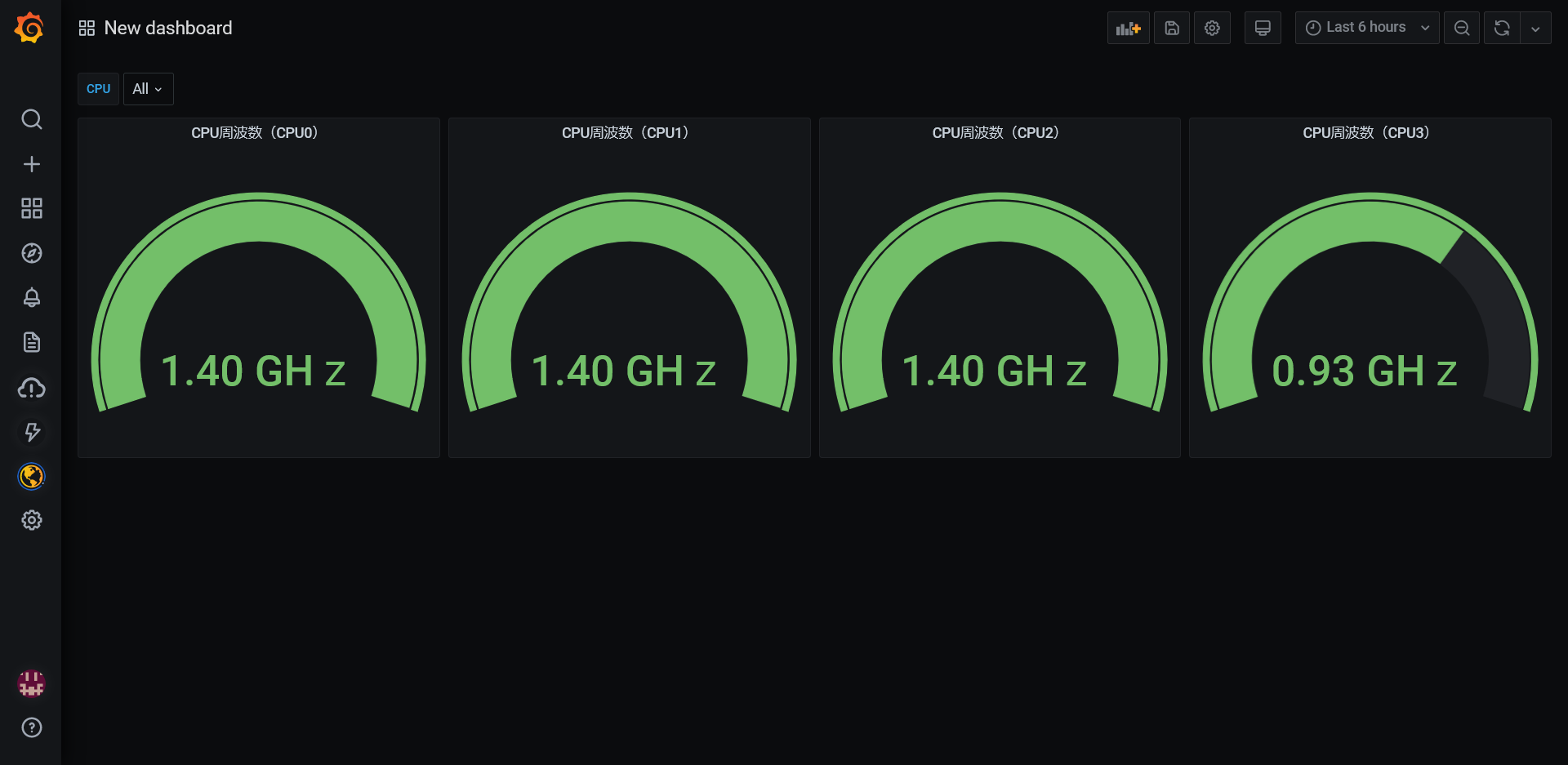
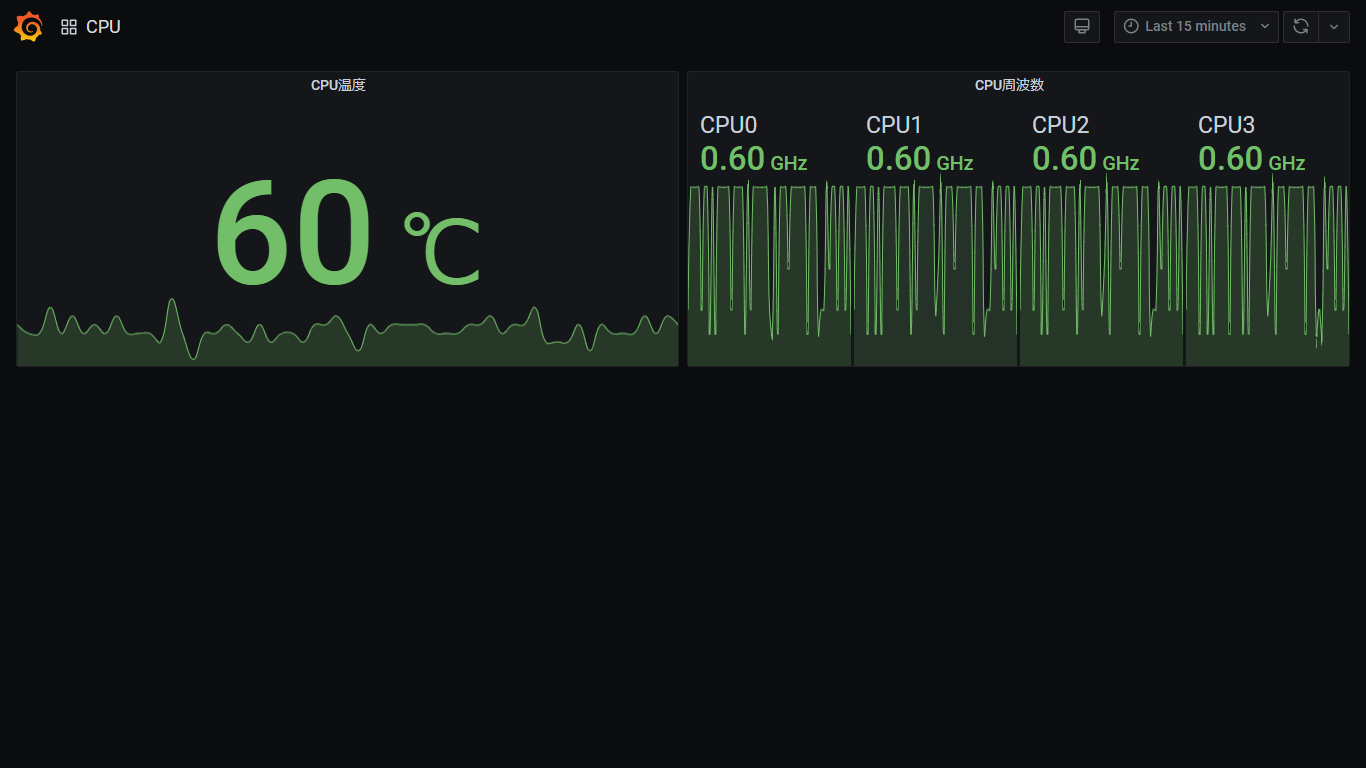
Amazon Managed Service for PrometheusとAmazon Managed Grafanaを使ってRaspberry Piのメトリクスを可視化してみました。(名前が長い。。そして統一感がない。。)
Amazon Managed Service for Prometheusのセットアップ
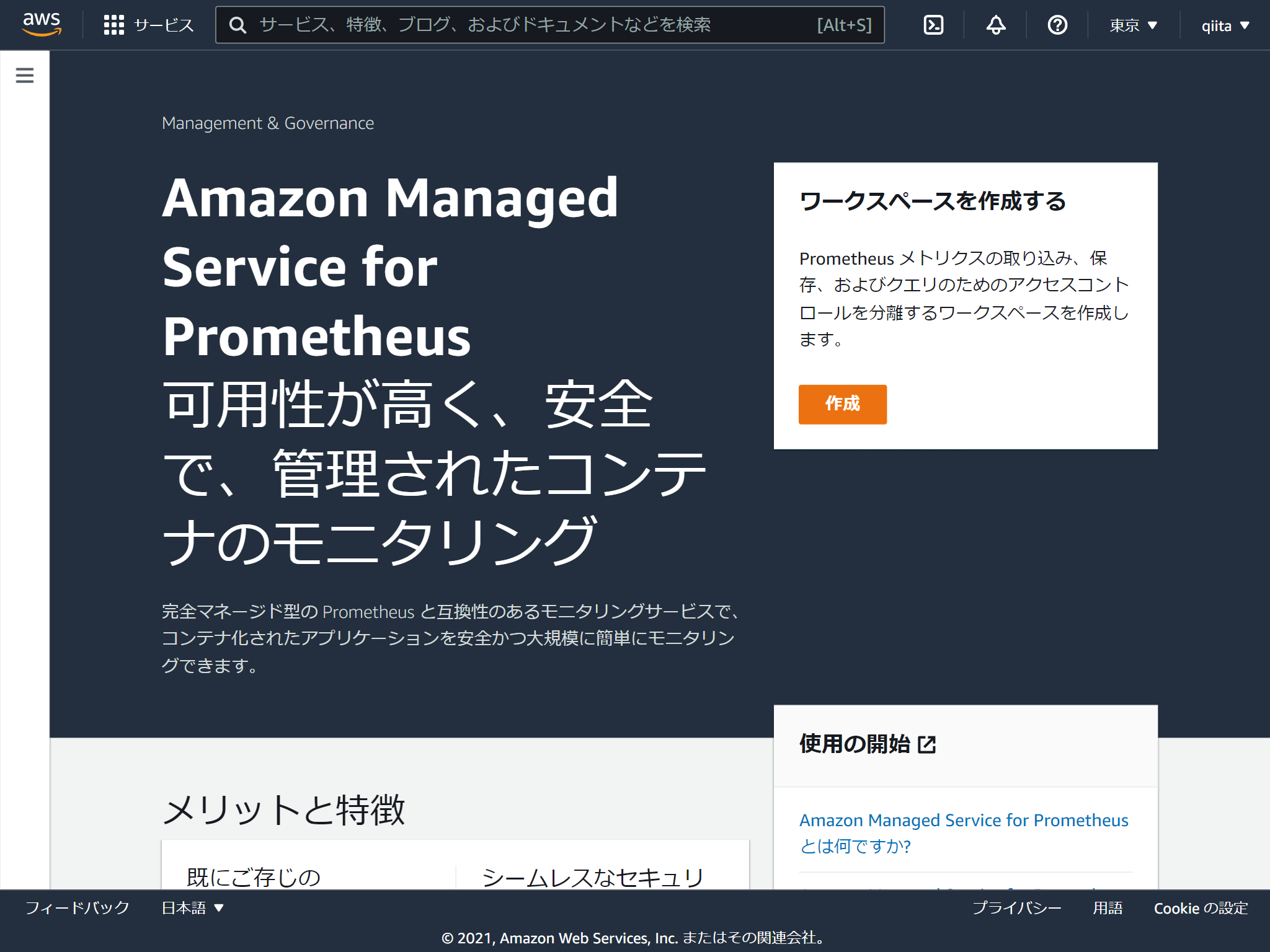
ワークスペースの名称を決めるだけです。
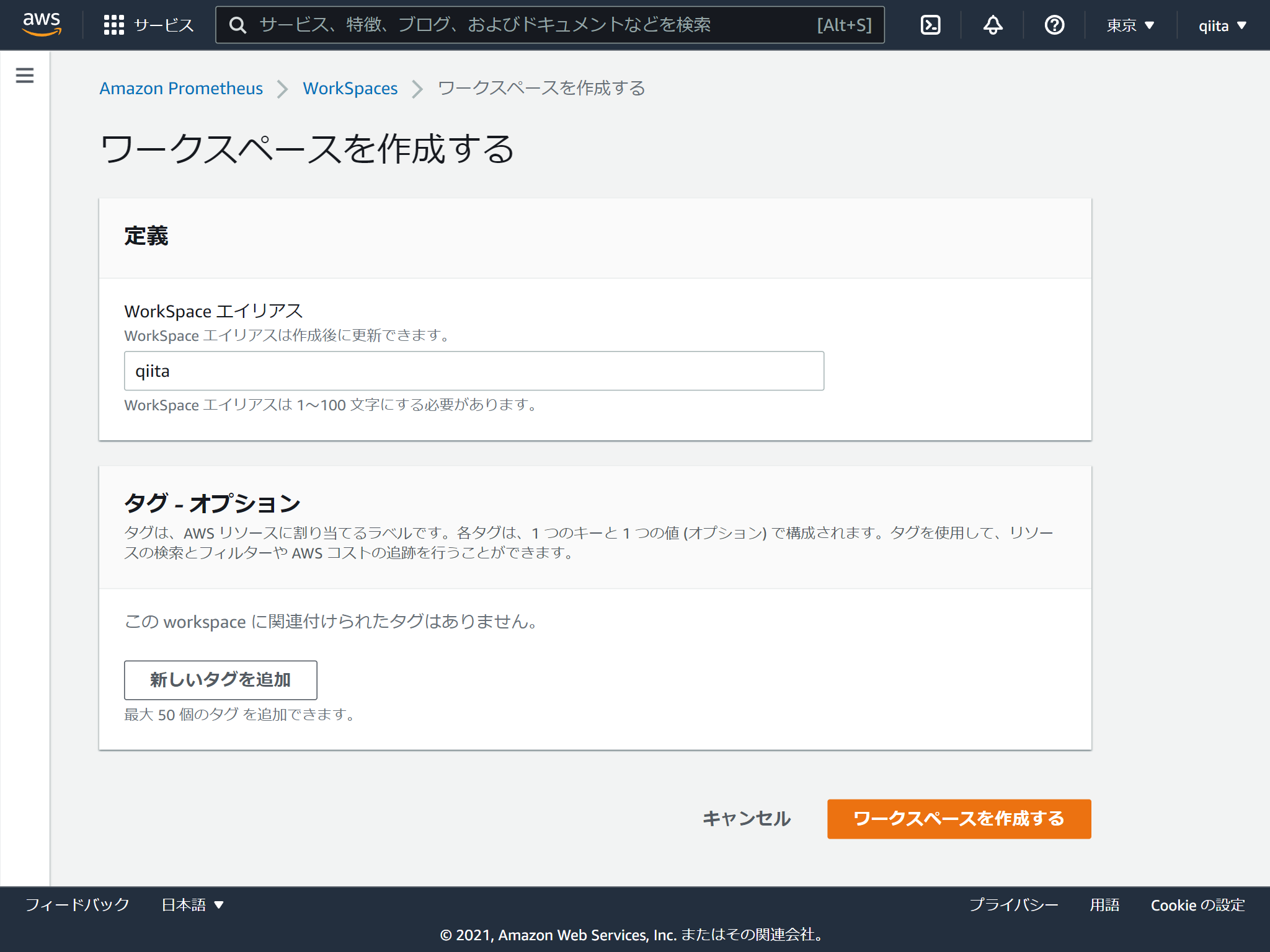
出来上がり。超簡単
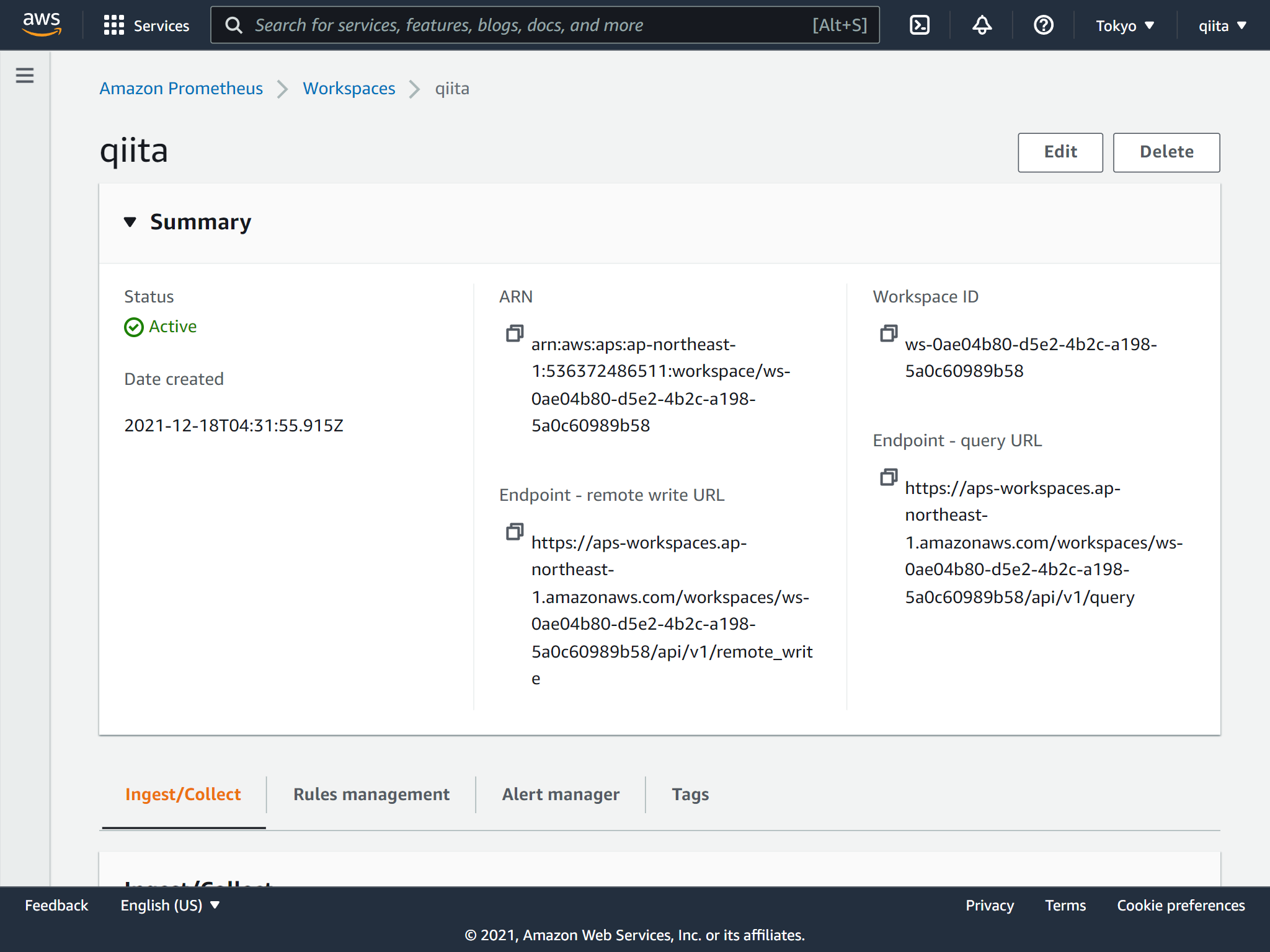
Raspberry Pi4からメトリクスを送信
IAMユーザーのアクセスキー情報が必要ですので、IAMユーザーを作成します。
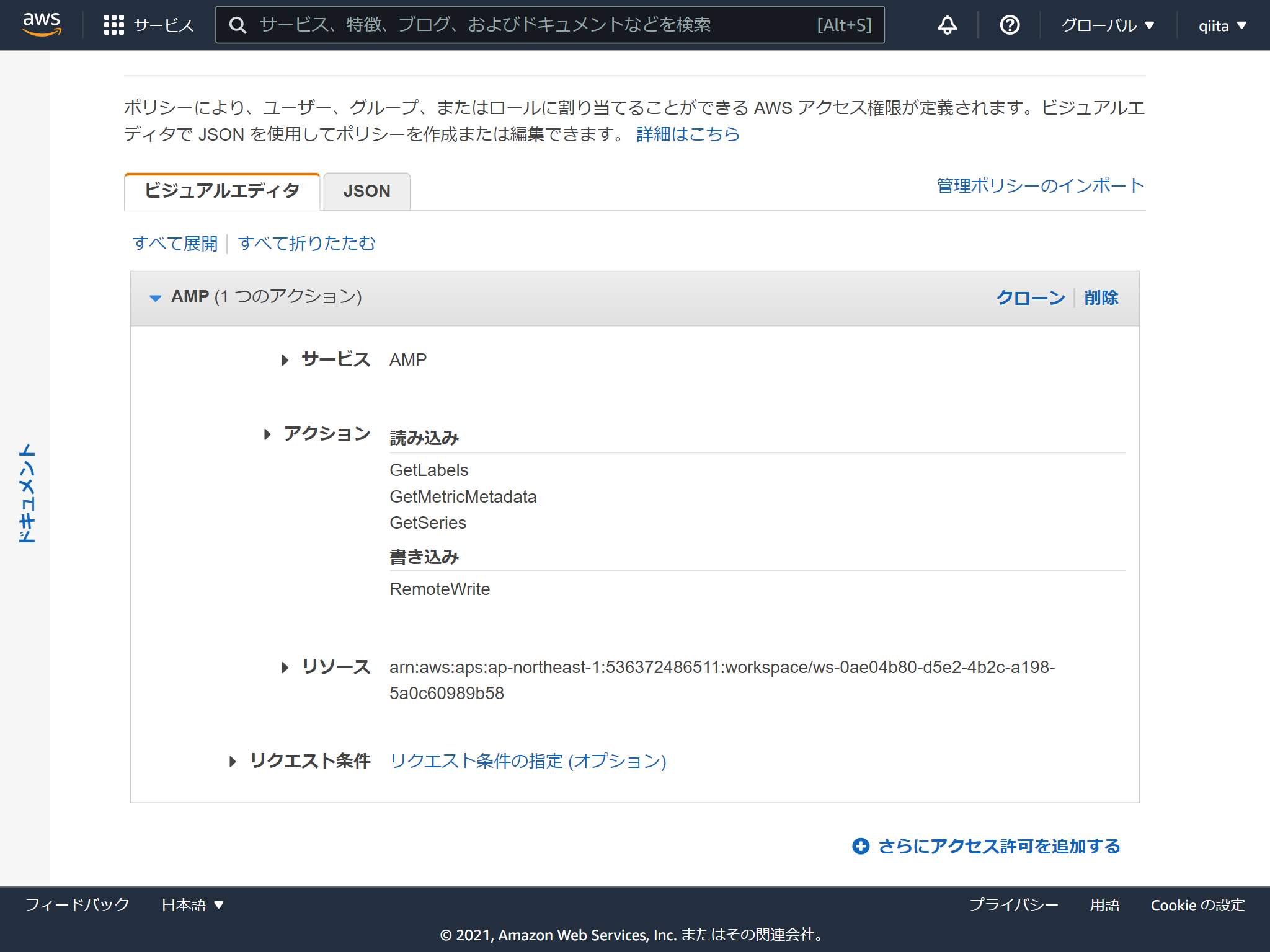
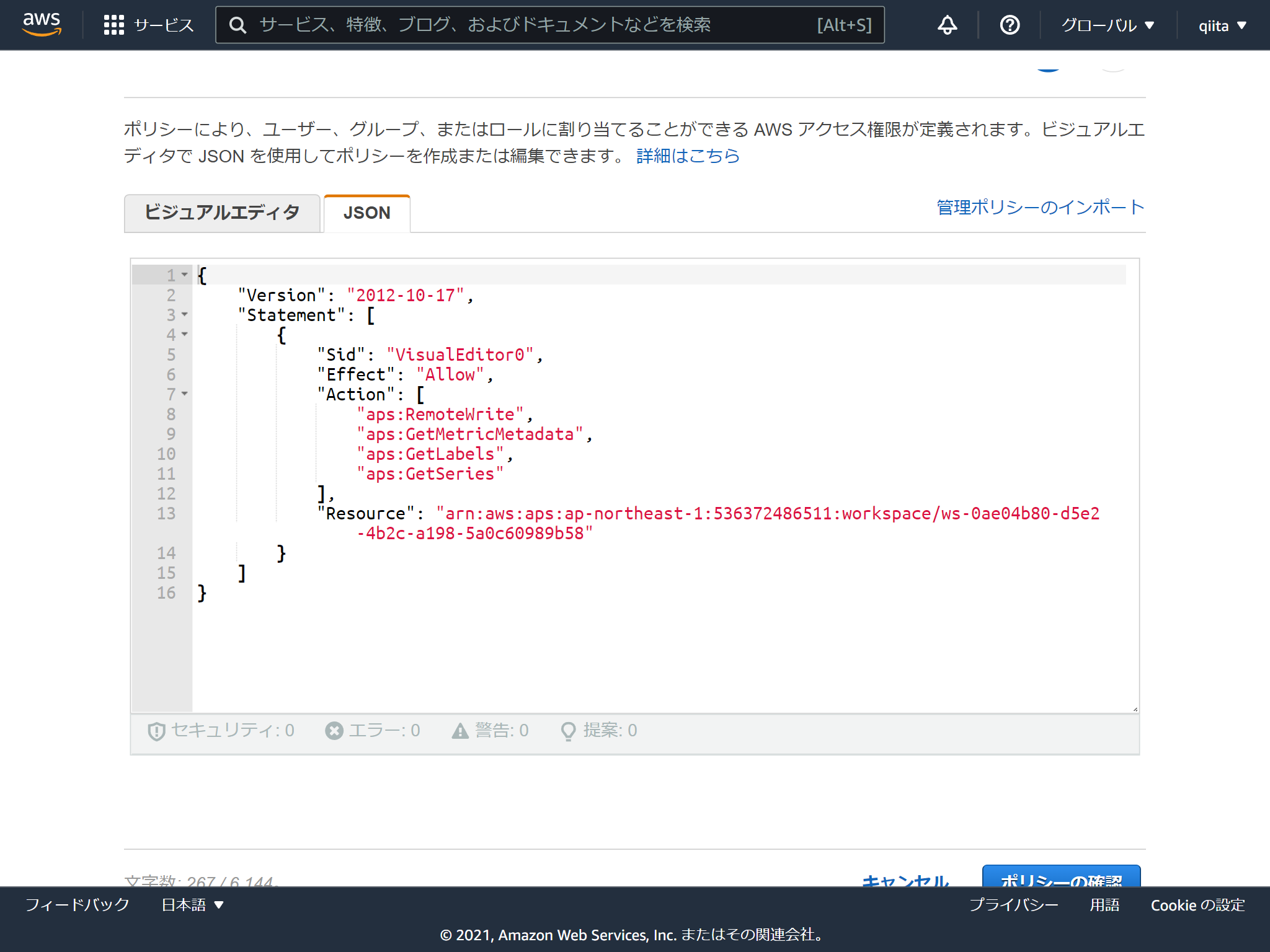
必要なポリシーはこんな感じです。aps:RemoteWriteだけでいいかもしれません。
注意点はなんといってもサービス名が AMP ってところです。さらにActionの接頭辞は aps (笑)
Docker ComposeでPrometheusとNode exporterを起動します。
docker-compose.yaml
version: '3.8'
services:
prometheus:
image: quay.io/prometheus/prometheus:latest
network_mode: host
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
node-exporter:
image: quay.io/prometheus/node-exporter:latest
container_name: node_exporter
command:
- '--path.rootfs=/host'
network_mode: host
pid: host
restart: unless-stopped
volumes:
- '/:/host:ro,rslave'
remote_writeのところに認証情報をセットします。
prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
rule_files:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
remote_write:
- url: https://aps-workspaces.ap-northeast-1.amazonaws.com/workspaces/ws-0ae04b80-d5e2-4b2c-a198-5a0c60989b58/api/v1/remote_write
sigv4:
region: ap-northeast-1
access_key: XXXXXXXXXXXXXXXXXXXX
secret_key: XXXXXXXXXXXXXXXXXXXX
起動します
Amazon Managed Grafanaのセットアップ
ワークスペース名をつけます
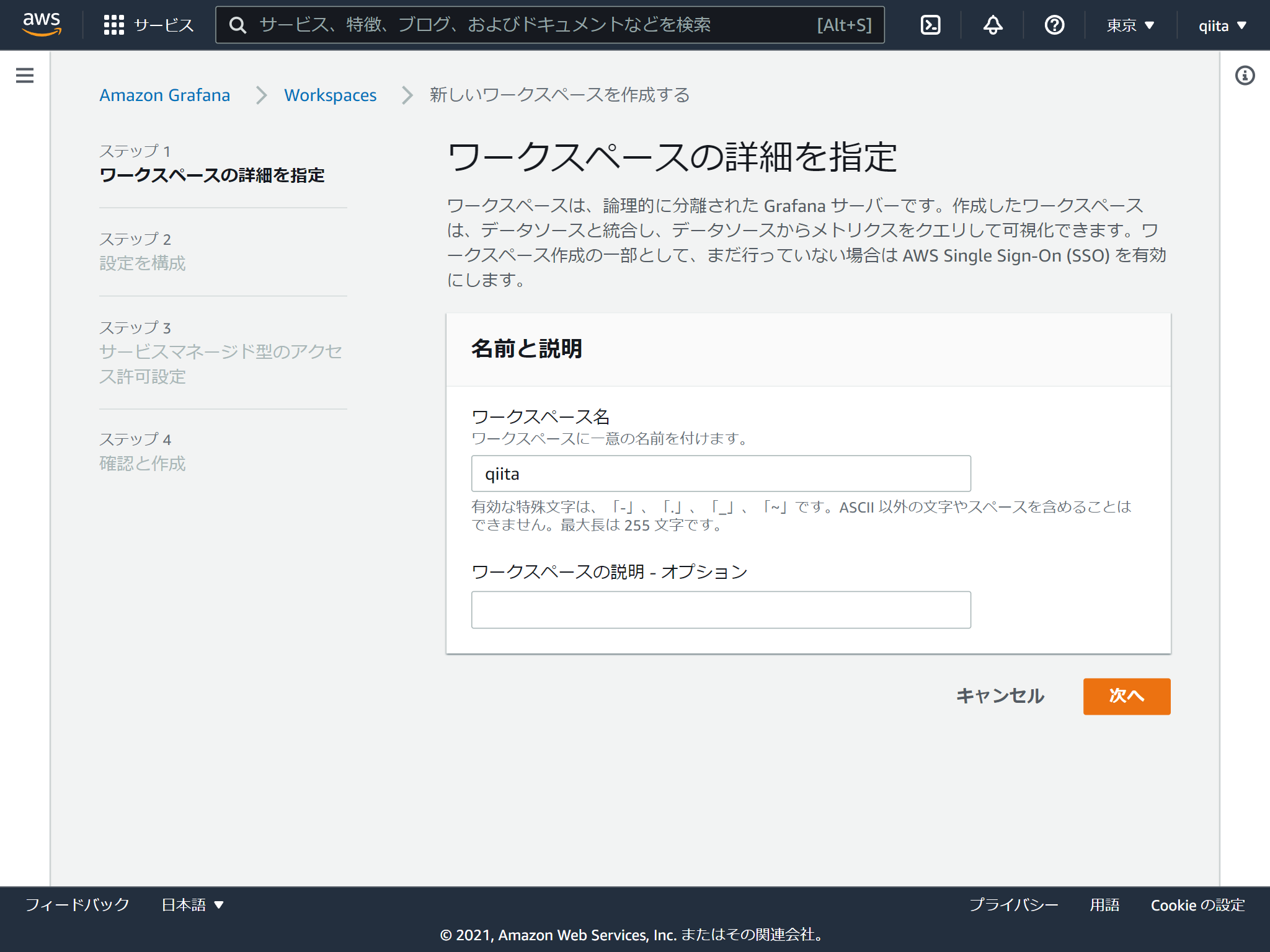
Grafanaの画面にログインする際に使う認証情報を選択します。AWS SSOにしてみました。
GrafanaがアクセスするAWSのリソースを選択します。
あとからも変更できます。
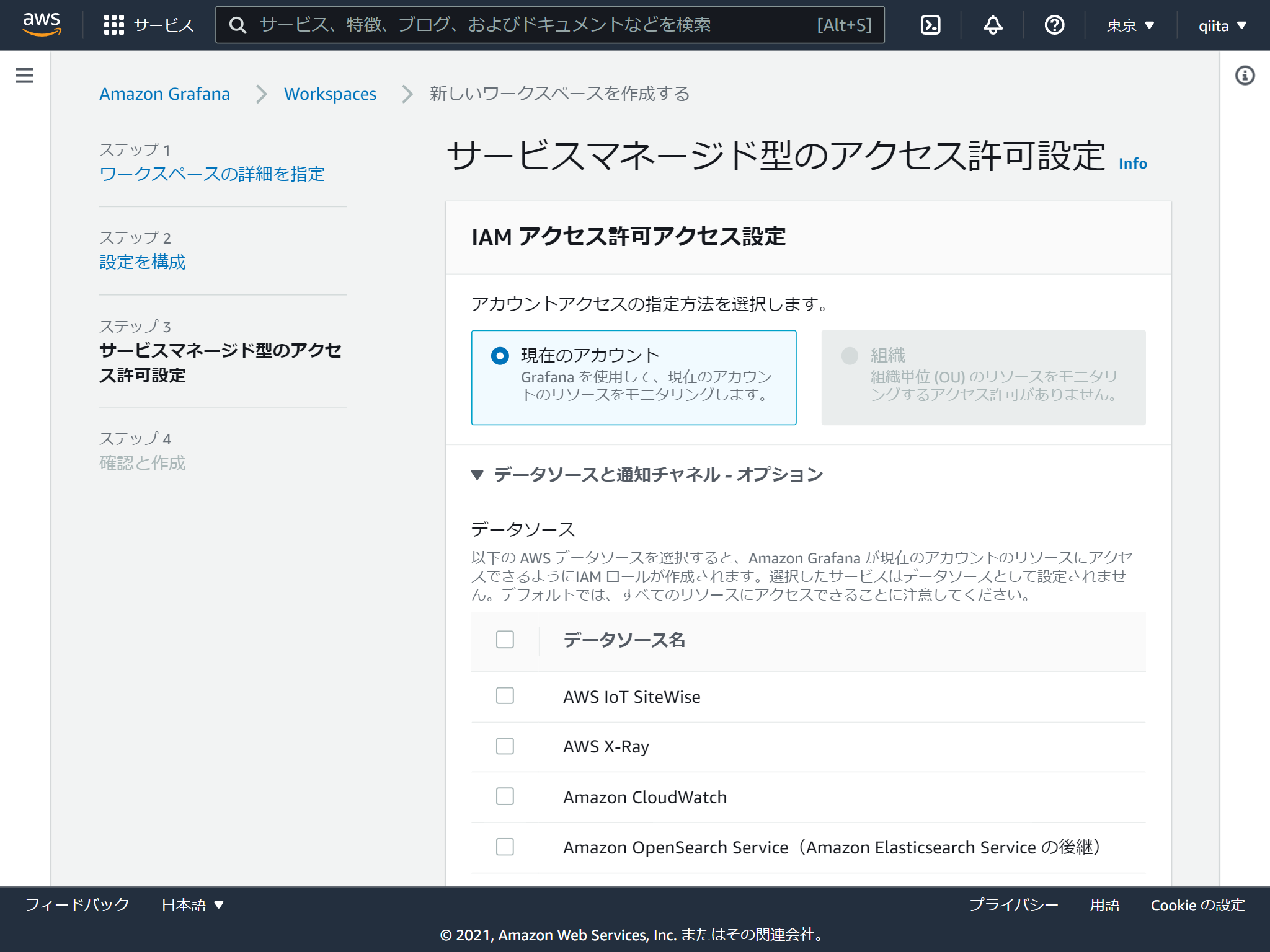
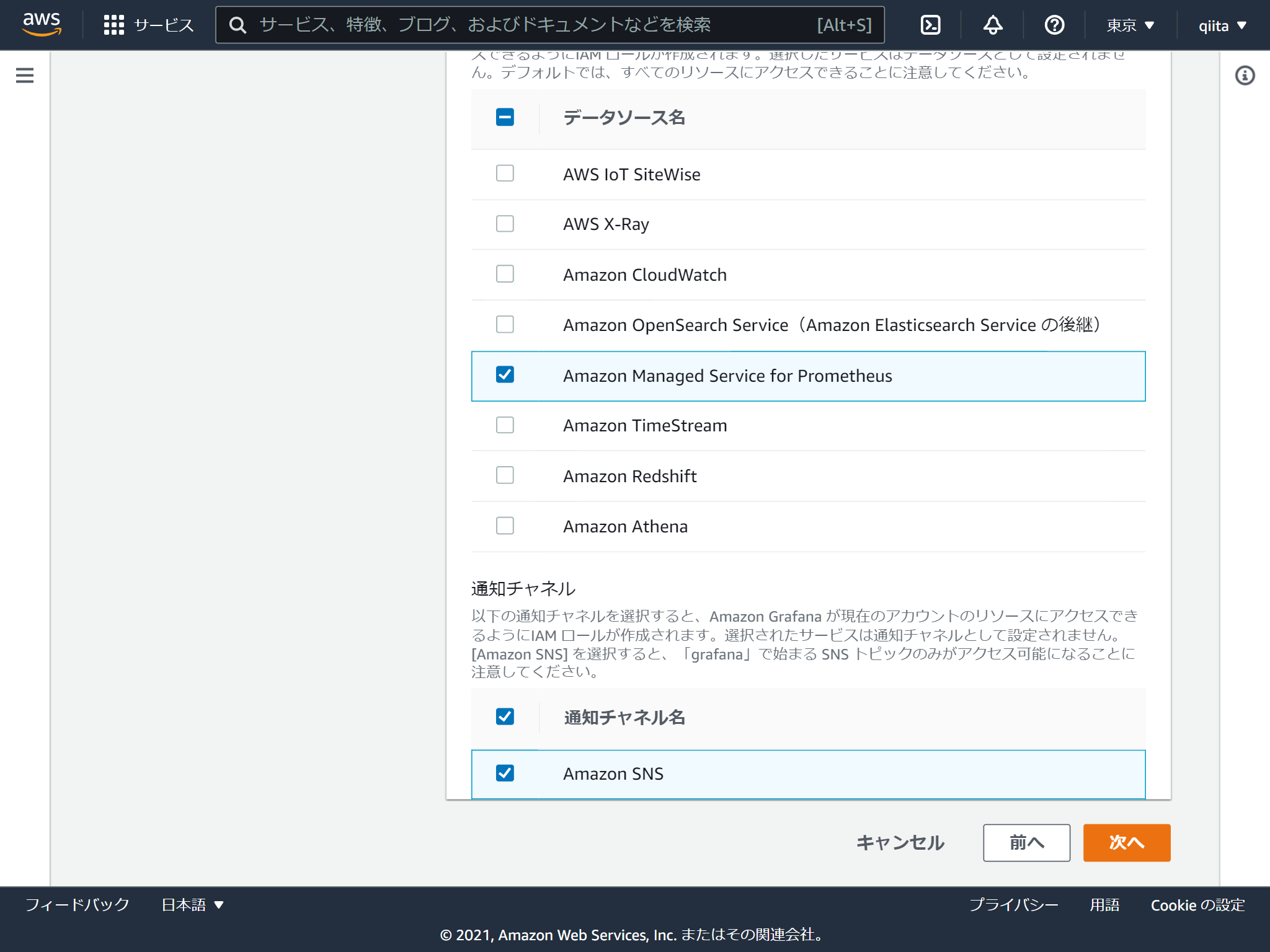
これで作成は完了です。
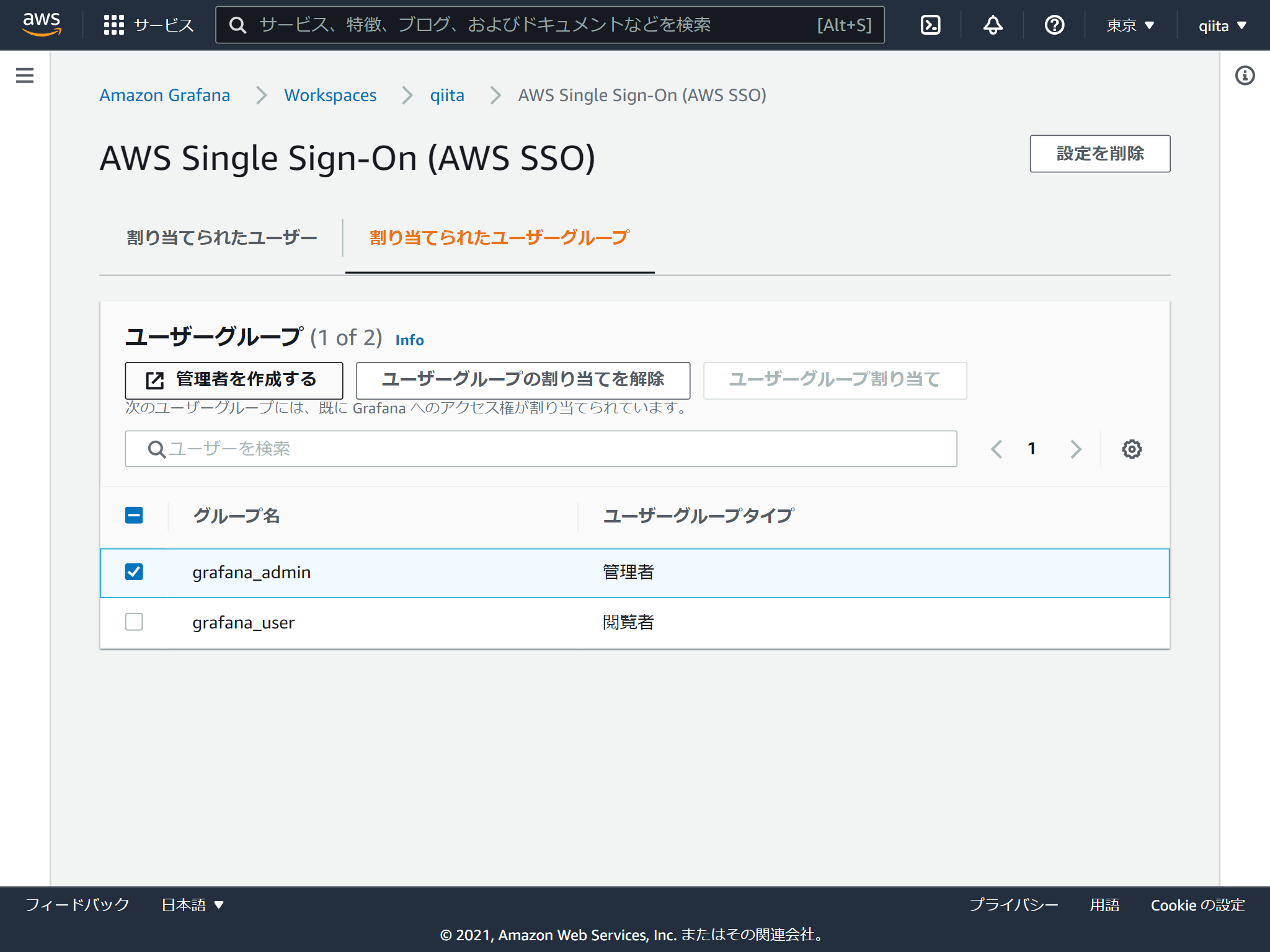
続いてログインするユーザーを追加します。「ユーザーとユーザーグループの設定」をクリック
今回はAWS SSOで作成したグループを追加します。
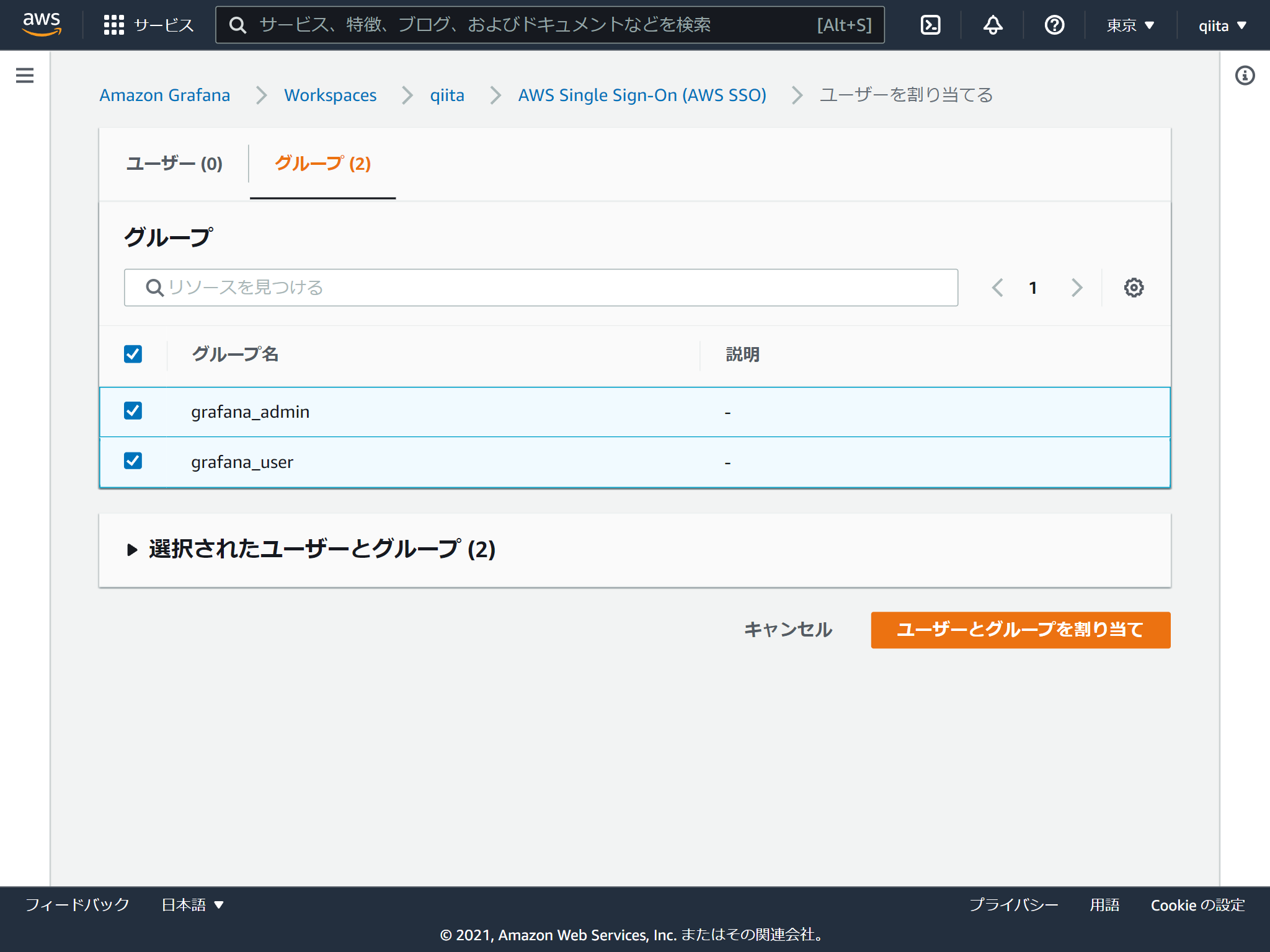
権限は閲覧者と管理者の2つあります。デフォルトが閲覧者で管理者に変更する場合はチェックを入れて「管理者を作成する」をクリックします。(閲覧者に戻す方法はないのかな?)
Grafanaログイン
マネジメントコンソールに表示されるワークスペースURLからアクセスします。設定したAWS SSOのユーザーでログインするとGrafanaの画面が表示されます。メニューにAWSのアイコンがありますね。
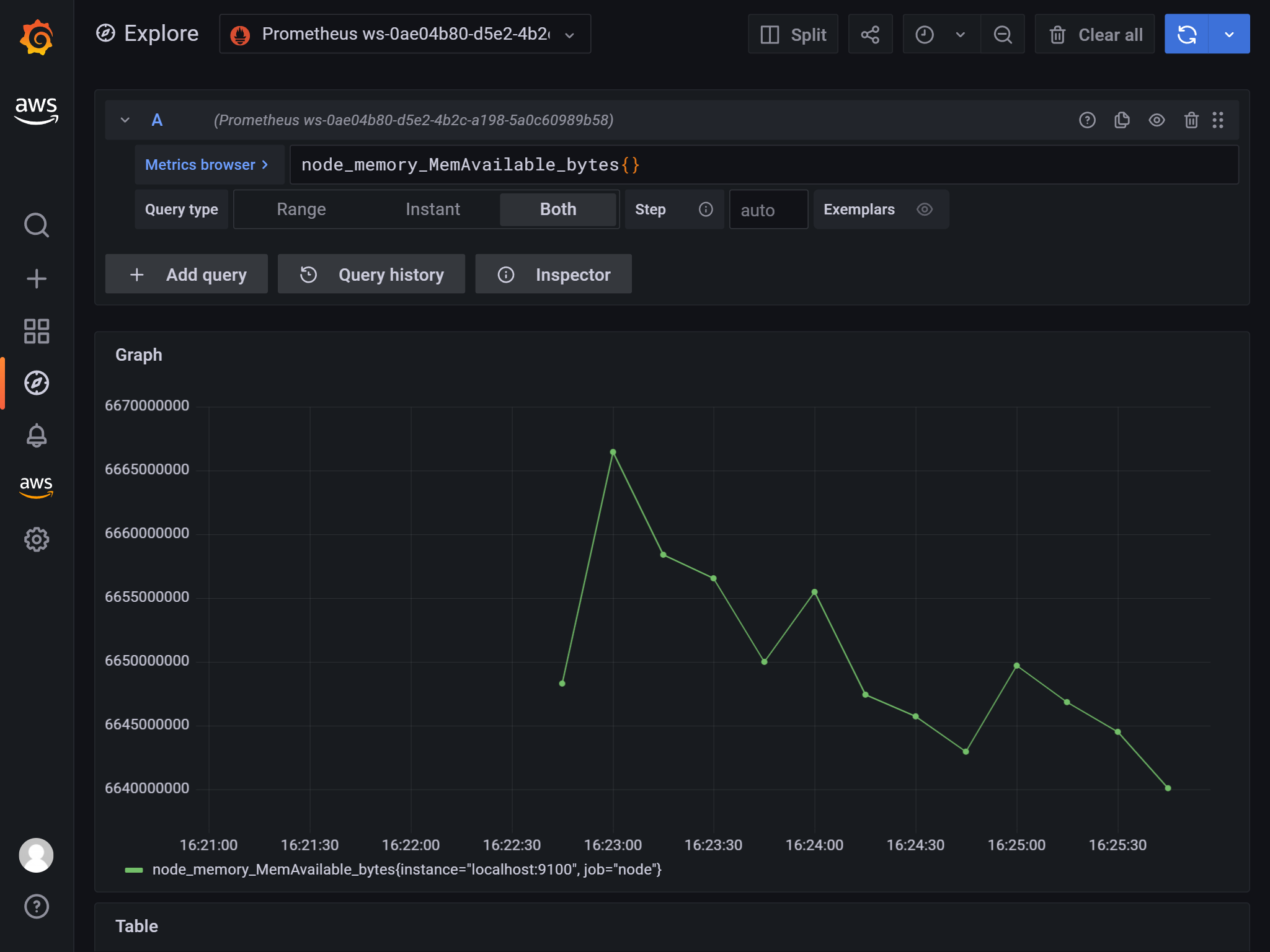
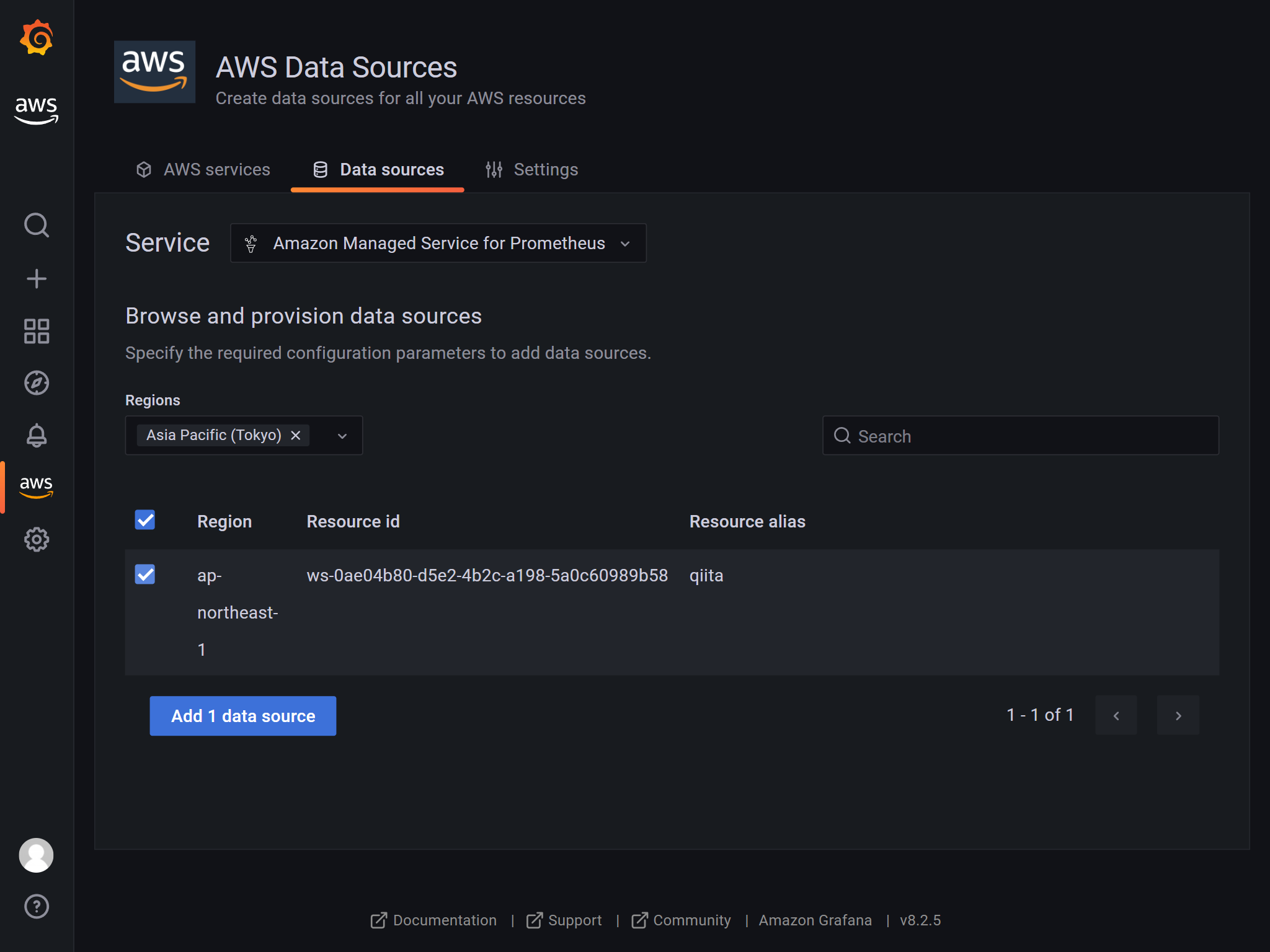
データソースにAmazon Managed Service for Prometheusを追加します。
AWSアイコンからデータソースをたどると追加できます。
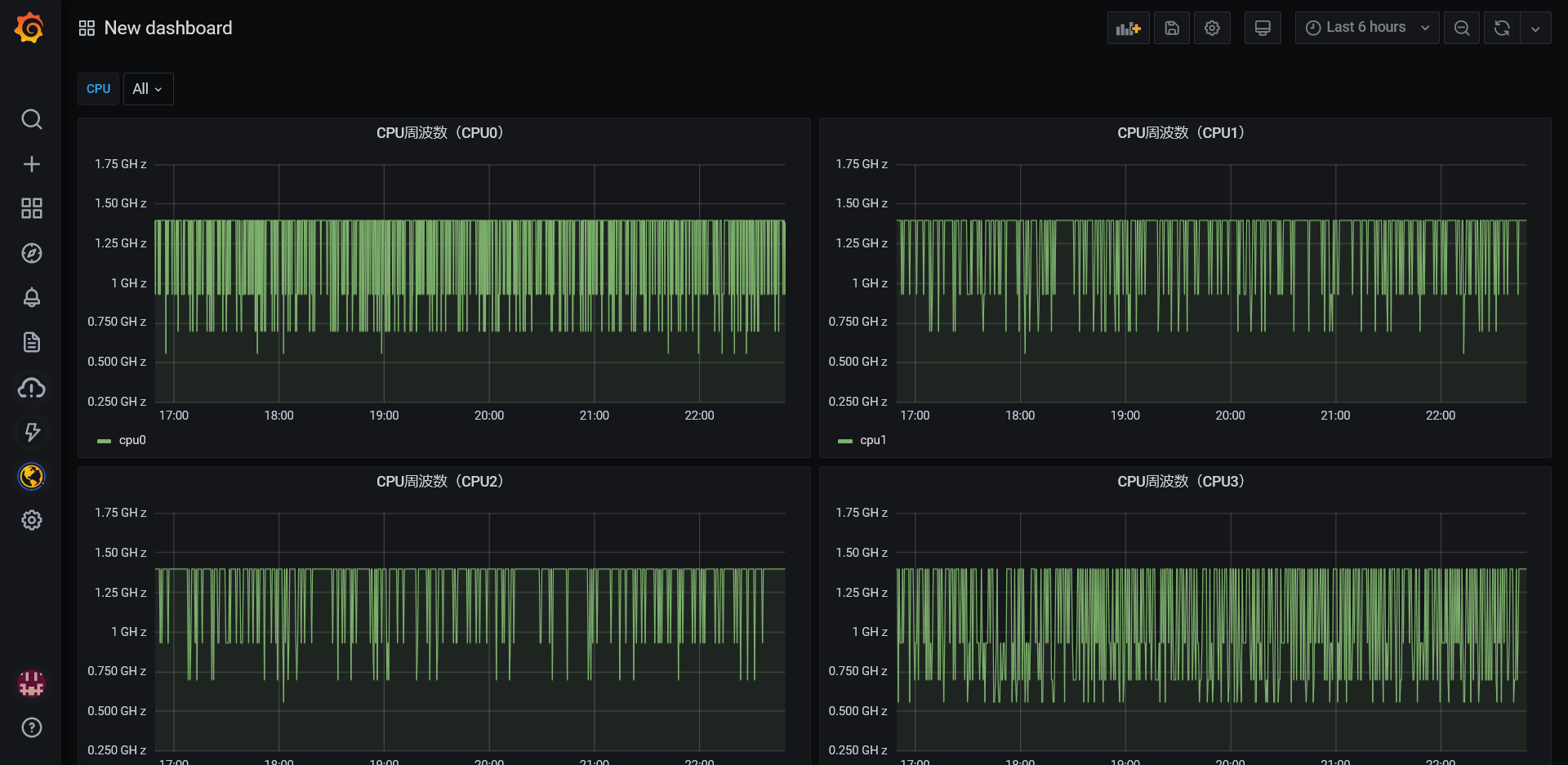
ここまでできれば通常のGrafana同様です。