import os
import requests
from bs4 import BeautifulSoup
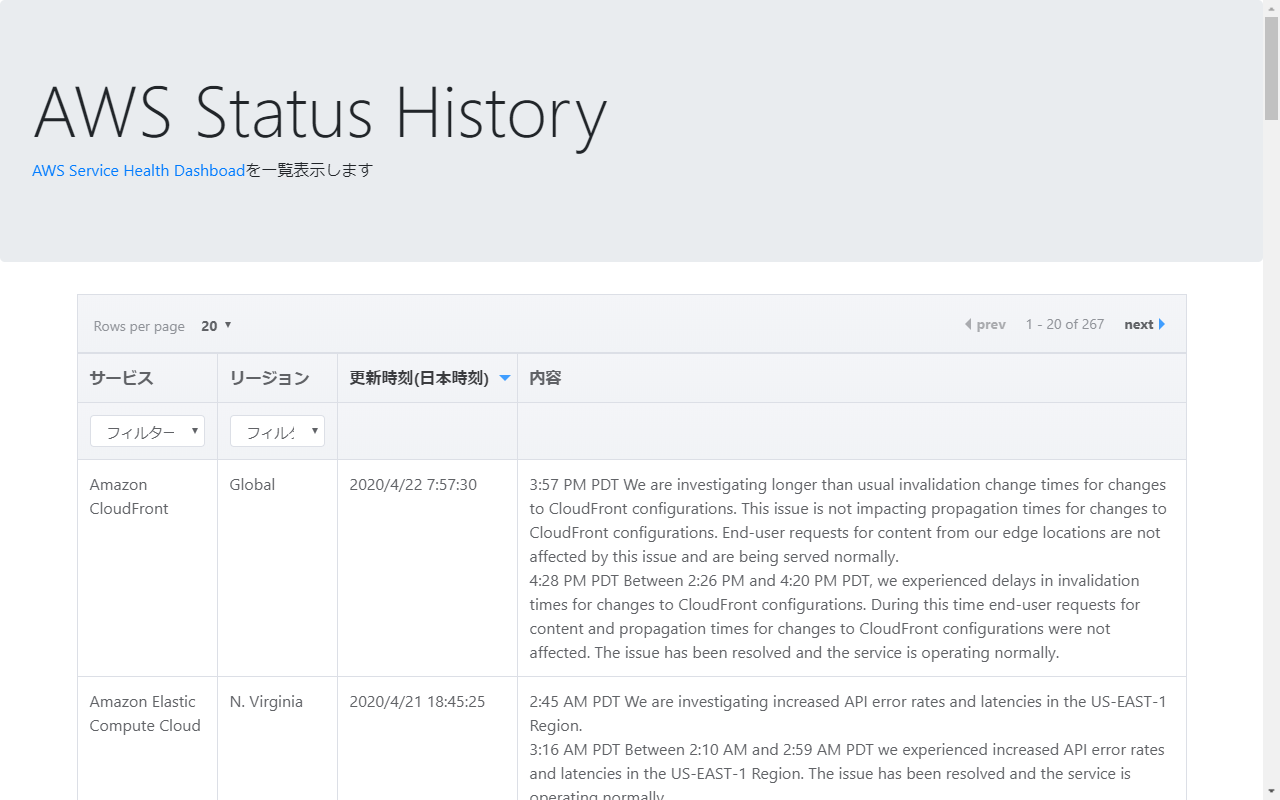
base_url = 'https://status.aws.amazon.com'
rss_template = ('<?xml version="1.0" encoding="UTF-8"?>'
'<rss version="2.0">'
' <channel>'
' <title><![CDATA[AWS Service Status]]></title>'
' <link>http://status.aws.amazon.com/</link>'
' <description><![CDATA[AWS Service Status]]></description>'
' </channel>'
'</rss>'
)
def get_rss_list(block):
print('start get_rss_list')
res = requests.get(base_url)
aws_soup = BeautifulSoup(res.text, 'lxml')
tables = aws_soup.find(id=block).find_all('table')
links = []
for tr in tables[1].find('tbody').find_all('tr'):
tds = tr.find_all('td')
links.append({'service': tds[1].text, 'url': tds[3].find('a').get('href')})
return links
def get_rss_item(rss_url):
print(rss_url)
response = requests.get(rss_url)
return response.text
def add_rss_item(rss_text, rss_path, service_name, output_soup):
rss = BeautifulSoup(rss_text, 'xml')
items = rss.find_all('item')
for item in items:
category = rss.new_tag('category')
category.append(service_name)
item.append(category)
output_soup.find('channel').append(item)
def put_object(rss_string, block):
import boto3
client = boto3.client('s3')
client.put_object(
ACL='public-read',
Body=rss_string.encode('utf-8'),
Bucket=os.getenv('S3_BUCKET'),
Key='aws-status'+block+'.rss',
ContentType='application/rss+xml'
)
def lambda_handler(event, context):
block = event['block']
print(block)
output_soup = BeautifulSoup(rss_template, 'xml')
for rss in get_rss_list(block):
url = base_url + rss['url']
text = get_rss_item(url)
add_rss_item(text, url, rss['service'], output_soup)
put_object(str(output_soup), block)