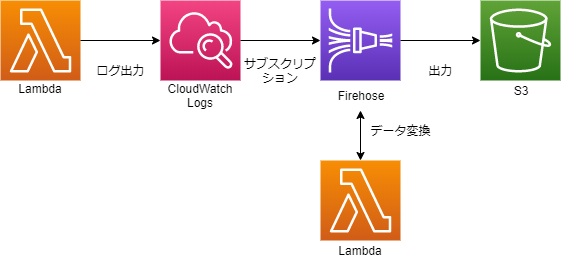
CloudWatch Logsに出力されたLambdaのログをS3に保管する方法です。
CloudWatch Logsのサブスクリプションという機能でログをKinesis Data Firehoseに送信します。
そのままS3に出力すると複数のログが1行に並ぶ形になってしまいますが、Kinesis Data Firehoseのデータ変換機能で改行を加えることで解決します。
こんな感じです。
S3バケットの作成
ログを出力するバケットを作成します。今回はlog-backup-xxxxxとします。
データ変換用Lambdaの作成
データ変換用LambdaはAWSが設計図を用意してくれているので簡単に作成できます。
マネジメントコンソールでLambda関数を作成します。
| 項目 | 選択 | 説明 |
|---|
| 作成方法 | 設計図の使用 | |
| 設計図 | kinesis-firehose-cloudwatch-logs-processor | Node.js版。Python2.7版のkinesis-firehose-cloudwatch-logs-processor-pythonもあります |
| 関数名 | kinesis-firehose-cloudwatch-logs-processor | 任意 |
| 実行ロール | 基本的なLambdaアクセス権限で新しいロールを作成する | |
ソース中にコメントに以下の記載があり、どのような形式のログが渡ってくるかがわかります。
処理手順も色々ありそうですが、そのあたりはすでに実装済みなので、変換する形式を変更したい場合はtransformLogEvent関数を修正するだけです。
設計図での実装は、付加情報は全部除外して、ログのメッセージに改行を付与して出力しています。
function transformLogEvent(logEvent) {
return Promise.resolve(`${logEvent.message}\n`);
}
例えば、logEventの内容をすべて出力し改行を付与する場合は、以下の様になると思います。
function transformLogEvent(logEvent) {
return Promise.resolve(`${JSON.stringify(logEvent)}\n`);
}
また、Amazon Kinesis Data Firehose CloudWatch Logs Processorというテストイベントも用意されているので、マネジメントコンソールで簡単にテストができます。
最後に、Lambdaのタイムアウトを1分以上にしておきましょう。
Kinesis Data Firehoseのストリームを作成
マネジメントコンソールで作成します。
| 項目 | 選択 | 説明 |
|---|
| Delivery stream name | CloudWatchLogs-to-S3 | 任意 |
| Choose a source | | |
| source | Direct PUT or other sources | |
| ---次のページ--- | | |
| Transform source records with AWS Lambda | | |
| Record transformation | Enabled | |
| Lambda function | kinesis-firehose-cloudwatch-logs-processor | 作成したLambda |
| Lambda function version | $LATEST | |
| Convert record format | | |
| Record format conversion | Disabled | |
| ---次のページ--- | | |
| Select a destination | | |
| Destination | Amazon S3 | |
| S3 destination | | |
| S3 destination | log-backup-xxxxx | 作成したバケット |
| S3 prefix | logs/ | |
| S3 error prefix | error/ | |
| S3 backup | | |
| Source record S3 backup | Disabled | |
| S3 buffer conditions | | |
| Buffer size | 5MB | デフォルト値 |
| Buffer interval | 300seconds | デフォルト値 |
| S3 compression and encryption | | |
| S3 compression | Disabled | |
| S3 encryption | Disabled | |
| Error logging | | |
| Error logging | Enabled | |
| Permissions | | |
| IAM role | Create new or choose | 新しくIAMロールを作成するといい感じにアクセス権限を付与してくれます |
CloudWatch Logsに付与するIAMロールを作成
このあとの手順で作成するCloudWatch Logsのサブスクリプションフィルターに、Firehoseにアクセスする権限が必要なので、IAMロールを作成します。
ただ、マネジメントコンソール上からは、CloudWatch Logsに付与するIAMロールはそのままでは作れないので、以下の手順で作成します。
まずはマネジメントコンソールでIAMロールを作成します。
| 項目 | 選択 | 説明 |
|---|
| 信頼されたエンティティの種類を選択 | AWSサービス | |
| このロールを使用するサービスを選択 | EC2 | |
| Attach アクセス権限ポリシー | なし | 次の手順で付与します |
| ロール名 | CWLtoKinesisFirehoseRole | |
| ロールの説明 | 削除 | 説明がEC2になってるので削除しておく |
次にIAMポリシーを作成します。
| 項目 | 選択 | 説明 |
|---|
| サービス1 | | |
| サービス | Firehose | |
| アクション | すべてのFirehoseアクション | |
| リソース | arn:aws:firehose:ap-northeast-1:[アカウントID]:deliverystream/CloudWatchLogs-to-S3 | 作成したFirehoseの配信ストリームのARN |
| サービス2 | | |
| サービス | IAM | |
| アクション | PassRole | |
| リソース | arn:aws:iam::[アカウントID]:role/CWLtoKinesisFirehoseRole | 作成したIAMロールのARN |
| ---次のページ--- | | |
| ポリシーの確認
| 名前 | Permissions-Policy-For-CWL |
再度IAMロールの編集画面に戻り、CWLtoKinesisFirehoseRoleロールにPermissions-Policy-For-CWLポリシーをアタッチします。
最後にCWLtoKinesisFirehoseRoleロールの信頼関係タブの信頼関係の編集をクリック。"Service": "ec2.amazonaws.com"の部分を"Service": "logs.ap-northeast-1.amazonaws.com"に変更し、保存します。
CloudWatch Logsサブスクリプションフィルターの作成
マネジメントコンソールからは作成できないようですので、CLIで作成します。
| パラメータ(キー) | パラメータ(値) | 説明 |
|---|
| --log-group-name | /aws/lambda/xxxxxx | サブスクリプションフィルターを追加したいロググループ名 |
| --filter-name | Logs-to-Firehose | 任意 |
| --filter-pattern | "" | フィルターせず、全ての場合 |
| --destination-arn | arn:aws:firehose:ap-northeast-1:[アカウントID]:deliverystream/CloudWatchLogs-to-S3 | 作成したFirehoseの配信ストリームのARN |
| --role-arn | arn:aws:iam::[アカウントID]:role/CWLtoKinesisFirehoseRole | 作成したIAMロールのARN |
aws logs put-subscription-filter --log-group-name [ロググループ名] --filter-name Logs-to-Firehose --filter-pattern "" --destination-arn arn:aws:firehose:ap-northeast-1:[アカウントID]:deliverystream/CloudWatchLogs-to-S3 --role-arn arn:aws:iam::[アカウントID]:role/CWLtoKinesisFirehoseRole
これで無事にS3にCloudWatchLogsがS3に保存されます。
GlueやAthenaでもクエリーがかけられそうです。
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/logs/SubscriptionFilters.html#FirehoseExample
https://docs.aws.amazon.com/ja_jp/firehose/latest/dev/data-transformation.html
https://docs.aws.amazon.com/cli/latest/reference/logs/put-subscription-filter.html
