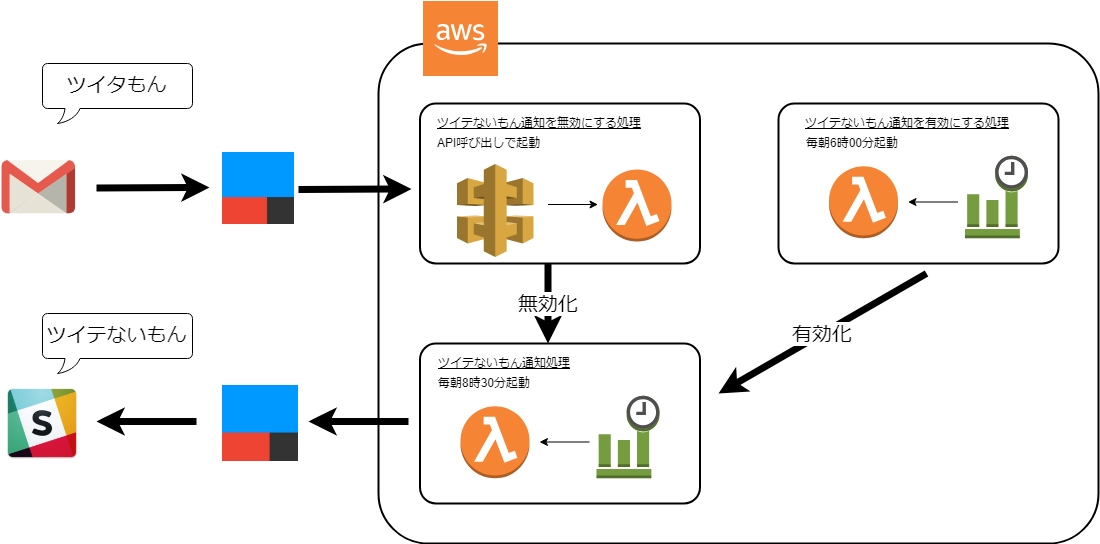
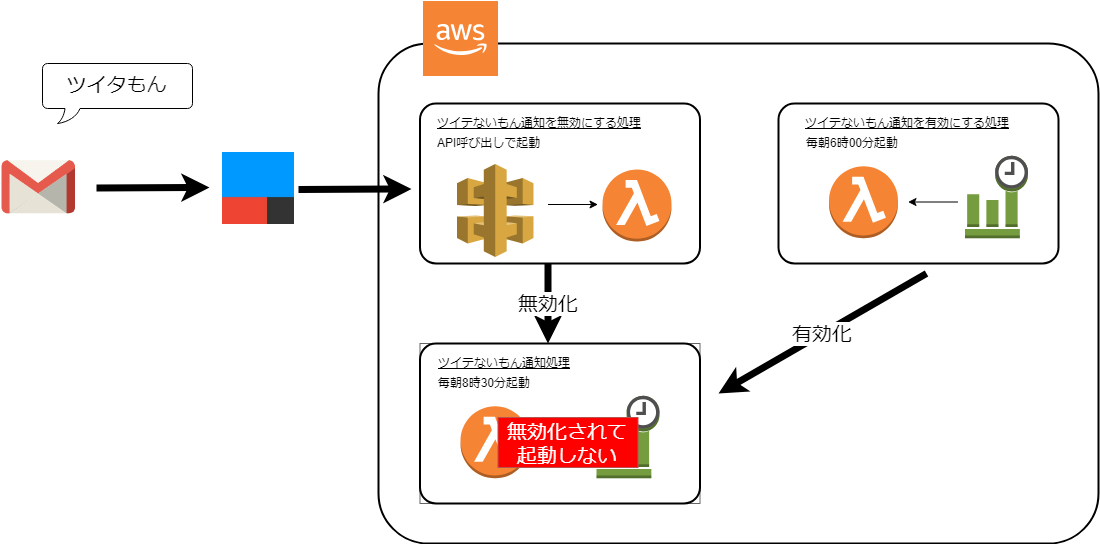
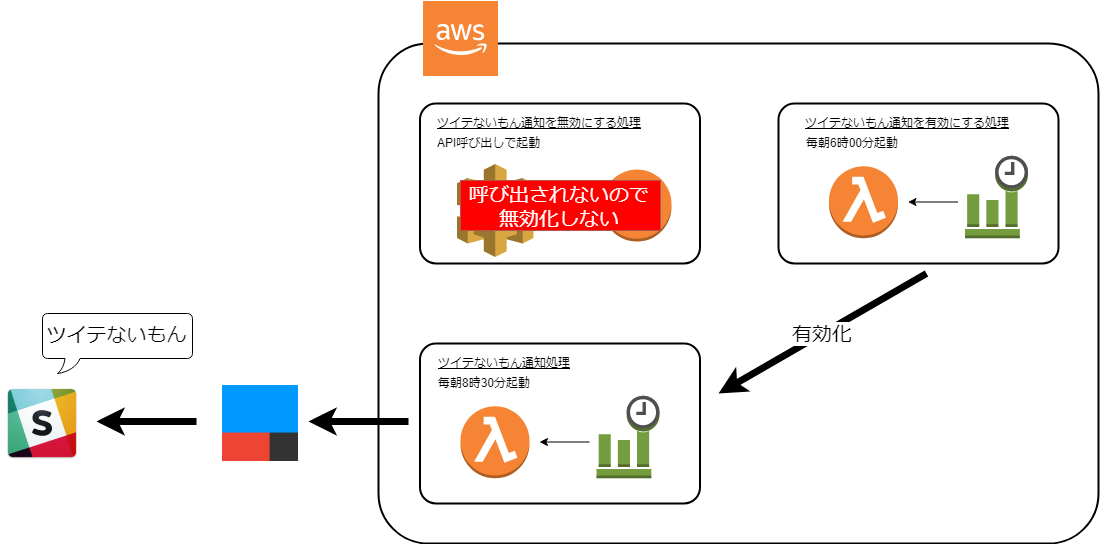
Amazonさんから招待が来たのでecho dotが手に入りました。
でもGoogle Homeも気になりますよね。
ということで、GoogleアシスタントをAlexa Skillにしてしまうことにしました。
12/20にGoogle Assistant SDKが0.4.0にバージョンアップし、日本語にも対応しています。
Alexa Skill Kitのセットアップ
細かい手順は他に任せるとして、要点を抜粋して紹介。
スキル情報
対話モデル
カスタム対話モデル
| Sample Utterances | Slot Type |
|---|
| {q} | qSlot (後述のカスタムスロット) |
カスタムスロットタイプ
| VALUE | ID (OPTIONAL) | SYNONYMS |
|---|
| 今日の天気は | | |
あまり理屈はわかりませんが、これで「今日の天気は」はもちろん、
その他の発話に対してもこの対話モデルが選択されます。
リクエストのJSONはこんな感じになります。
{
"session": {
},
"request": {
"type": "IntentRequest",
"requestId": "XXXXXXXXXX",
"intent": {
"name": "NewIntent",
"slots": {
"q": {
"name": "q",
"value": "こんにちは"
}
}
},
"locale": "ja-JP",
"timestamp": "XXXXXXXXXX"
},
"context": {
},
"version": "1.0"
}
以上でAlexa Skillの設定は完了です。
CentOSとPython環境の構築
MacのVirtualBox上にCent OS 7の環境を構築しました。
Python 3.6のインストールとvirtualenv環境のセットアップ
Lambdaのデプロイパッケージ作成の手順を参考にしました。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/with-s3-example-deployment-pkg.html
[centos@localhost ~]$ sudo yum install -y gcc zlib zlib-devel openssl openssl-devel
[centos@localhost ~]$ wget https://www.python.org/ftp/python/3.6.1/Python-3.6.1.tgz
[centos@localhost ~]$ tar -xzvf Python-3.6.1.tgz
[centos@localhost ~]$ cd Python-3.6.1 && ./configure && make
[centos@localhost ~]$ sudo make install
[centos@localhost ~]$ /usr/local/bin/virtualenv ~/shrink_venv
[centos@localhost ~]$ source ~/shrink_venv/bin/activate
(shrink_venv) [centos@localhost ~]$
Google Assistant SDKのセットアップ
公式ドキュメントにそって進めます。
Set Up Hardware and Network Access
https://developers.google.com/assistant/sdk/guides/library/python/embed/setup
→省略。
https://developers.google.com/assistant/sdk/guides/library/python/embed/audio
→今回は音声の入出力は必須ではないので、省略します。
https://developers.google.com/assistant/sdk/guides/library/python/embed/config-dev-project-and-account
→ドキュメントに沿って実施。
あとで以下のものが必要になります。
- 作成したプロジェクト名
以下の説明ではAlexa-GoogleAssistant-Skillがプロジェクト名となります。 client_secret_<client-id>.json ファイル
Do not rename this file. とあるのでファイル名もダウンロードしたままで維持する必要があるようです。
CentOS環境上にコピーしてください。
Install the SDK and Sample Code
https://developers.google.com/assistant/sdk/guides/library/python/embed/install-sample
→ドキュメントに沿って実施。ただし、Pythonの環境構築はすでに実施していますので、その部分は飛ばします。
必要なライブラリーの導入
(shrink_venv) [centos@localhost ~]$ python -m pip install --upgrade google-assistant-library
(shrink_venv) [centos@localhost ~]$ python -m pip install --upgrade google-assistant-sdk[samples]
credentialsの生成
(shrink_venv) [centos@localhost ~]$ google-oauthlib-tool --scope https://www.googleapis.com/auth/assistant-sdk-prototype \
--save --headless --client-secrets [client_secret_client-id.json]
client_secret_client-id.jsonは、Google Assistant SDKのセットアップの手順で作成したものです。ファイルパスを指定してください。
コマンドを実行すると以下のように入力待受状態になりますので、メッセージ中のURLにアクセスしてコードを取得してください。
Please visit this URL to authorize this application: https://accounts.google.com/o/oauth2/auth?xxxxxxxxxx
Enter the authorization code:
コード入力後、以下のメッセージが表示されます。
credentials saved: /home/ubuntu/.config/google-oauthlib-tool/credentials.json
保存されたファイルの中身は以下のような形です。この文字列が後で必要になります。
credentials.json (整形済み)
{
"token_uri": "XXXXXXXXXX",
"client_id": "XXXXXXXXXX",
"refresh_token": "XXXXXXXXXX",
"scopes": [
"XXXXXXXXXX"
],
"client_secret": "XXXXXXXXXX"
}
Register the Device
https://developers.google.com/assistant/sdk/guides/library/python/embed/register-device
→ドキュメントに沿って実施。
SDKのバージョン0.4.0から追加された手順と思います。
(shrink_venv) [centos@localhost ~]$ googlesamples-assistant-devicetool register-model --manufacturer "Assistant SDK developer" \
--product-name "Alexa-GoogleAssistant-Skill" --type LIGHT --model Alexa-GoogleAssistant-Skill-Model
--manufacturerはサンプルのまま、--product-nameはなんでもOK?、--typeは必須なのでとりあえずLIGHT、--modelはグローバルユニークな文字列である必要があるようです。
モデル名について
Note that this name must be globally unique so you should use your Google Developer Project ID as a prefix to help avoid collisions (for example, my-dev-project-my-model1).
Run the Sample Code
https://developers.google.com/assistant/sdk/guides/library/python/embed/run-sample
サンプルを実行します。
(shrink_venv) [centos@localhost ~]$ googlesamples-assistant-hotword --project_id Alexa-GoogleAssistant-Skill --device_model_id Alexa-GoogleAssistant-Skill-Model
device_model_id: Alexa-GoogleAssistant-Skill-Model
device_id: XXXXXXXXXX
...
--project_idはGoogle Developer上で作成したプロジェクト名、--device_model_idは先程決めたモデル名です。
初回実行時にデバイスIDが自動生成されるようです。
このデバイスIDは後ほど必要になります。
マイクに向かってOK Googleというと反応すると思います。
今回はLambda化が目的なので、Ctrl+cで抜けて問題ありません。
Google Assistant SDKの日本語対応
https://developers.google.com/assistant/sdk/guides/assistant-settings
ドキュメントが上の手順からの続きではありませんのでご注意。
デバイス登録がうまくできると、AndroidアプリのGoogleアシスタントの設定に登録したデバイスが表示されます。
そのデバイスの設定で、言語設定ができます。
たぶん。
また、SDKの呼び出しパラメーターにlang設定があるので、ja-JPを設定すると、日本語で返事をしてくれます。
以上でGoogle Assistant SDKのセットアップは完了です。
Lambdaファンクションの作成
Google Assistant SDKのサンプル
ドキュメントには記載がないのですが、サンプルの中に、音声ではなくテキストを入力してテキストを返すものが含まれていました。
(shrink_venv) [centos@localhost ~]$ python -m googlesamples.assistant.grpc.textinput --device-model-id [デバイスモデルID] --device-id [デバイスID]
E1230 11:54:46.796841462 2399 ev_epollex_linux.cc:1482] Skipping epollex becuase GRPC_LINUX_EPOLL is not defined.
E1230 11:54:46.796894329 2399 ev_epoll1_linux.cc:1261] Skipping epoll1 becuase GRPC_LINUX_EPOLL is not defined.
E1230 11:54:46.796909730 2399 ev_epollsig_linux.cc:1761] Skipping epollsig becuase GRPC_LINUX_EPOLL is not defined.
INFO:root:Connecting to embeddedassistant.googleapis.com
: Hello
Hello
<@assistant> What can I do for you?
: What time is it now
What time is it now
<@assistant> It's 11:55.
: Good bye
Good bye
<@assistant> Goodbye
: ^CAborted!
(shrink_venv) [centos@localhost ~]$
ソースはGitHubにありましたので、これを改良してLambda化を目指します。
https://github.com/googlesamples/assistant-sdk-python/blob/master/google-assistant-sdk/googlesamples/assistant/grpc/textinput.py
textinputサンプルからの変更点
以下の点を変更します。
- サンプルでは
Ctrl+cで抜けるまでやり取りが続けられましたが、1回の応答で処理を終了するように変更 - デバイスモデル名、デバイスIDを環境変数で指定できるように変更
- credentials.jsonについてはファイルパスではなくてjson文字列を環境変数で指定できるように変更
- (当然ですが)Lambdaの作法に合わせる対応
- (当然ですが)Alexaからのリクエストを受けれるように、また、Alexaの求めるレスポンスが返せるように変更
Lambdaファンクション
出来上がったソースがこちら。
ソース全体はこちら。
---省略---
credentials_json = os.getenv('GA_CREDENTIALS','{"token_uri": "token_uri", "client_id": "client_id", "refresh_token": "refresh_token", "scopes": ["scopes"], "client_secret": "client_secret"}')
lang = os.getenv('GA_LANG', 'en-US') # en-US, ja-JP
device_model_id = os.getenv('GA_DEVICE_MODEL_ID', 'XXXXX')
device_id = os.getenv('GA_DEVICE_ID', 'XXXXX')
error_msg=os.getenv('GA_ERROR_MSG', 'No Response')
---省略---
def assist(text_query):
credentials = google.oauth2.credentials.Credentials(token=None,
**json.loads(credentials_json))
http_request = google.auth.transport.requests.Request()
credentials.refresh(http_request)
# Create an authorized gRPC channel.
grpc_channel = google.auth.transport.grpc.secure_authorized_channel(
credentials, http_request, api_endpoint)
with textinput.SampleTextAssistant(lang, device_model_id, device_id,
grpc_channel, grpc_deadline) as assistant:
text_response = assistant.assist(text_query=text_query)
return text_response
---省略---
def lambda_handler(event, context):
text_query=text_query=event['request']['intent']['slots']['q']['value']
logging.info('Query text is %s', text_query)
text_response = assist(text_query=text_query)
if text_response == None:
logging.info('Response text is None')
text_response = error_msg
logging.info('Response text is %s', text_response)
session_attributes={}
card_title=text_query+' -> ' + text_response
speech_output=text_response
reprompt_text=text_response
should_end_session=True
return build_response(session_attributes, build_speechlet_response(
card_title, speech_output, reprompt_text, should_end_session))
---省略---
デプロイパッケージの作成
AWSのドキュメントを参考にしました。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/with-s3-example-deployment-pkg.html
(shrink_venv) [centos@localhost ~]$ cd $VIRTUAL_ENV
(shrink_venv) [centos@localhost shrink_venv]$ cd lib/python3.6/site-packages/
/home/ubuntu/env
(shrink_venv) [centos@localhost site-packages]$ zip -r9 ~/DeployPackage.zip *
(shrink_venv) [centos@localhost site-packages]$ cd ~
(shrink_venv) [centos@localhost ~]$ zip -g ~/DeployPackage.zip lambda_function.py
作成したzipファイルをマネジメントコンソールからアップロードし、Lambdaファンクションとして登録します。
終わりに
- 複数回の会話のやり取りはできません。改良の余地あり
- 応答が複数に別れる場合に最後の部分しか返答がありません。SDKの仕様?
- となりにおいていたAndroidスマホも「オーケーグーグル」に反応して同じ答えを返します(声は違うけど)。😀
- 結局、天気を聞くぐらいしか用途がありません。😀