AWSのアイコンを検出できるAIを作りました😀😀😀 完成したAIはこちら
きっかけ
AWSのサービスがたくさんあるので、サービスのアイコンもたくさんあります。2022/6/15時点でこれだけあります。 全291個!!




当然、これ全部覚えられるわけもなく、これを見分けられるAIができたら面白いかなと思い、挑戦してみました。
とにかく多いです。人間には覚えられませんが、AIなら覚えられるかもしれませんので挑戦します
フレームワークの調査
画像の中から画像を探すので、物体検出(Object Detection)という種類のAIを作成します。Object Detectionができるフレームワークを調査しました。
調べていると、どうもYOLOv5が良さそうなので、これを使ってみることにしました。
今後も新しいフレームワークがどんどん出てくると思います。
YOLOv5を使ってみる
まずはGitHubの手順に従って実施してみます。
- インストール
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt
簡単です。(他にもpipでもインストールができました。)
- 推論
予め学習済みのモデルが用意されているのでいきなり物体検出が可能です。
curl -L https://ultralytics.com/images/zidane.jpg -o img.jpg
python detect.py --source img.jpg
実行すると結果がruns/detect/expフォルダーに出力されます。 学習済みのモデルは当然ながらAWSのアイコンを検出してはくれないので、自前でモデルを作成しようと思います。
この精度でAWSのアイコンが判別できるとすごいですね。
学習までの手順
1.画像データの準備
まずは学習用データの準備です。AWSのアイコン画像はこちらで配布されているものを使用します。アセットパッケージとして提供されているPNG画像をもとに学習させます。
https://aws.amazon.com/jp/architecture/icons/
ダウンロードしたzipファイルの中には様々なサイズの画像が用意されていますが、今回はArch_64フォルダー内のpng画像(80px x 80px)を使用します。 @5x.pngというファイル名の、サイズが5倍の画像も用意されていますが、大きすぎる気がしたので使用しませんでした。
2.画像の水増し
AWSのサービスアイコンは一つのサービスに付き一つだけです(当たり前ですが)。学習のためにたくさんの画像を用意する必要があるため、プログラム的に水増しします。
KerasのImageDataGeneratorを使用して画像の水増しを行います。少しずつ位置をずらしたり、縦横を拡縮しています。色味も少し変化させています。
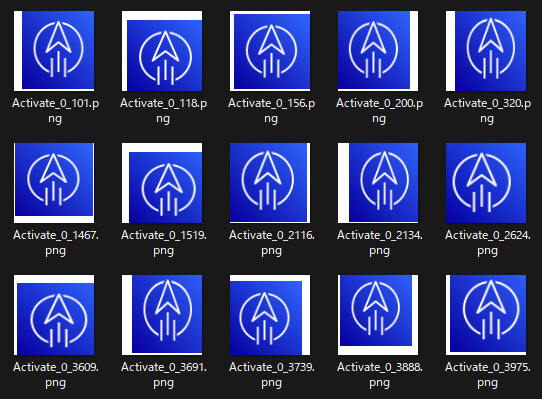
KerasのImageDataGeneratorでは他に回転させたり反転させる事もできましたが、AWSの構成図を作る際に、画像が回転したり反転したりすることはあまりないと思ったので、こういった変形はあえてしませんでした。
この方法で、1サービスアイコンにつき、100枚ずつの画像に水増しさせました。
少しずつ異なる画像を用意することでAIの学習精度が向上します
3.ラベルの準備
各画像がどの種類のサービスなのか、また、画像中のどの位置に対象の画像があるかをテキストデータで用意する必要があります。
ラベルのファイル名は画像のファイル名と対になっており、Activate_0_101.pngの画像のラベルはActivate_0_101.txtとして作成します。
ラベルの内容は以下のようなもので、左から順番に
・クラス番号 ・対象の中心のX座標(画像全体の幅を1.0とした際の座標) ・対象の中心のY座標(画像全体の高さを1.0とした際の座標) ・対象の幅(画像全体の幅を1.0とした際の幅) ・対象の高さ(画像全体の高さを1.0とした際の高さ)
となっています。
4.設定ファイルの作成
準備した画像とラベルの情報を記載した設定ファイルを作成します。
train: ../train_yolo5/images
val: ../val_yolo5/images
nc: 290
names: ['API-Gateway', 'Activate', ...]
また、このタイミングで学習用データセットと検証用データセットに分けます。
- trainは学習データとなる画像ファイルのフォルダ
- valは検証データとなる画像ファイルのフォルダ
- ncは識別するクラス数
- クラスの名称(0から順番)
手順は難しくないのですが、大量の画像に対して行うため、手作業では無理があります。次の章でPythonでの実施方法を紹介します。
学習データの準備
ここまでの手順を手作業で行うのは無理がありますので、以下のPythonスクリプトで実施しました。
- importと定数の定義
import glob
import os
import pathlib
import shutil
import numpy as np
import tensorflow as tf
TARGET_DIR = 'train_image'
TRAIN_IMAGE = 'train_image'
VAL_IMAGE = 'val_image'
TRAIN_DIR = 'train_yolo5'
VAL_DIR = 'val_yolo5'
TRAIN_LABEL_DIR = 'train_yolo5/labels'
VAL_LABEL_DIR = 'val_yolo5/labels'
TRAIN_IMAGE_DIR = 'train_yolo5/images'
VAL_IMAGE_DIR = 'val_yolo5/images'
- 画像の水増し
## 必要な画像をコピーして水増し
def collect_target_image():
image_generator = tf.keras.preprocessing.image.ImageDataGenerator(
zoom_range=[0.9, 1.1],
# rotation_range=2,
width_shift_range=0.1,
height_shift_range=0.1,
# channel_shift_range=10.0,
fill_mode='constant',
cval=255
)
try:
shutil.rmtree(TARGET_DIR)
except:
pass
try:
os.mkdir(TARGET_DIR)
except:
pass
files = glob.glob(
f'Architecture-Service-Icons_*/**/*64.png', recursive=True)
for file in files:
f = pathlib.Path(file)
f.name
name = f.stem.replace(
'Arch_AWS-', '').replace('Arch_Amazon-', '').replace('Arch_', '').replace('_64', '')
original_dir = f'{TARGET_DIR}/{name}'
original_file = f'{original_dir}/{name}.png'
try:
os.mkdir(original_dir)
shutil.copyfile(f, original_file)
except:
pass
target_img = tf.keras.preprocessing.image.load_img(original_file)
target_img = np.array(target_img)
x = target_img.reshape((1,) + target_img.shape)
generator = image_generator.flow(x,
save_to_dir=original_dir,
save_prefix=name,
save_format='png')
for i in range(100):
generator.next()
- 学習データと検証データの分割
## 学習データと検証データの分割
def split_val():
try:
os.mkdir(VAL_IMAGE)
except:
pass
dirs = os.listdir(TRAIN_IMAGE)
for dir in dirs:
try:
os.mkdir(f'{VAL_IMAGE}/{dir}')
except :
pass
files = os.listdir(f'{TRAIN_IMAGE}/{dir}')
for file in files[:10]:
shutil.move(f'{TRAIN_IMAGE}/{dir}/{file}', f'{VAL_IMAGE}/{dir}/')
- ラベルファイルの作成
## ラベルファイルの作成
def create_label():
try:
os.mkdir(TRAIN_DIR)
os.mkdir(VAL_DIR)
os.mkdir(TRAIN_LABEL_DIR)
os.mkdir(VAL_LABEL_DIR)
except:
pass
dirs = sorted(os.listdir(TRAIN_IMAGE))
for i, dir in enumerate(dirs):
train_files = os.listdir(f'{TRAIN_IMAGE}/{dir}')
for file in train_files:
with open(f'{TRAIN_LABEL_DIR}/{file[:-4]}.txt', 'w') as f:
f.write(f'{i} 0.5 0.5 1.0 1.0')
val_files = os.listdir(f'{VAL_IMAGE}/{dir}')
for file in val_files:
with open(f'{VAL_LABEL_DIR}/{file[:-4]}.txt', 'w') as f:
f.write(f'{i} 0.5 0.5 1.0 1.0')
data.yamlは手作業で作った気がします。
コードで書くとそれほどの分量にはならないですね。
学習の実行
学習の実行はコマンド一発です。
python train.py --data ../data.yaml --weights yolov5s.pt
これだけですが、私の非力なPCでは 丸二日 かかりました。😂😂😂 GPUがついているような強力な環境だともっと早いと思われます。 学習が終わるとruns/train/expに結果が出力されます。推論に使うモデルはこのフォルダの中にあるweights/best.ptです。
途中で心配になりましたが、無事、モデルを作成することができました。
推論の実行
作成したモデルでの推論はこのように実行します。
python detect.py --weight runs/train/exp/weights/best.pt --source ../target/
--sourceで直接ファイルを指定することもできますし、フォルダ指定もできます。
ではモデルの精度を確認してみましょう。
検証
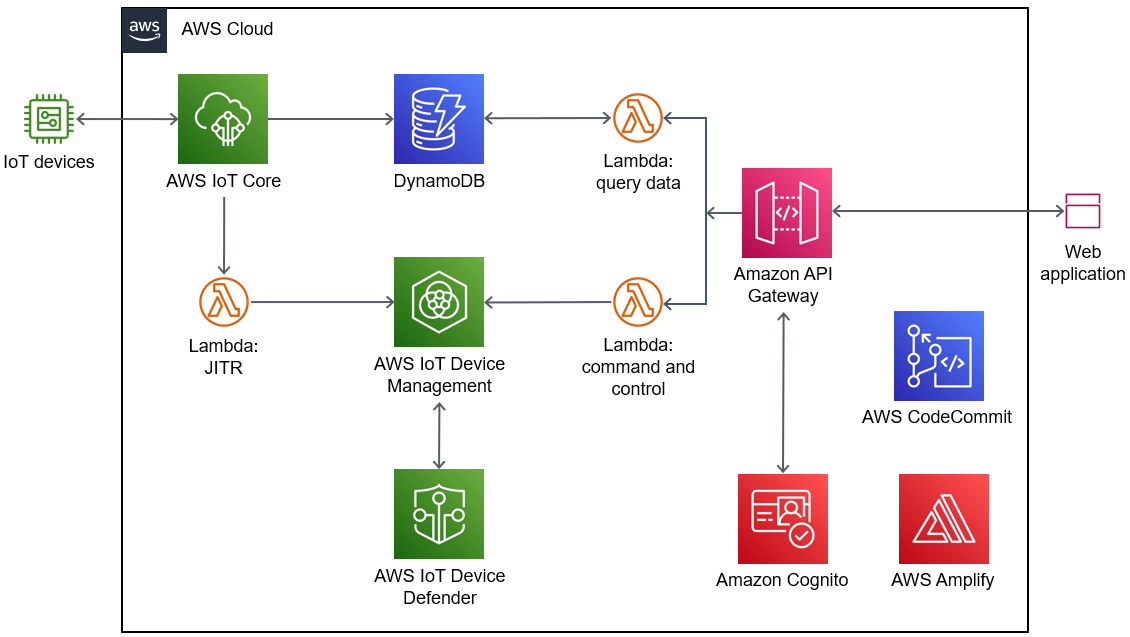
結果①

なんじゃこりゃ~~~~~
大失敗じゃないか!!!
2日もかけて作成したモデルがこの結果。。
よく見ると、Marketplaceが山のように検出されています。
| アイコン | サービス名 |
|---|---|
 | Marketplace Dark |
 | Marketplace Light |
なんとなく誤検知しそうな匂いがしますね。
再度学習させるのは大変なので(丸2日かかるので)、他の方法を探したところ、推論時に検出するクラスを指定する方法がありました。
python detect.py --weight runs/train/exp/weights/best.pt --source ../target/ --classes 0 1 2 3 4 5 6 7 8 9 10
Marketplaceのアイコン2つ 以外 のクラスをすべて引数で指定するとこうなります。(力技ですw)
python detect.py --weight runs/train/exp/weights/best.pt --source ../target/ --classes 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288
Marketplaceを除外した結果がこちら。
結果②
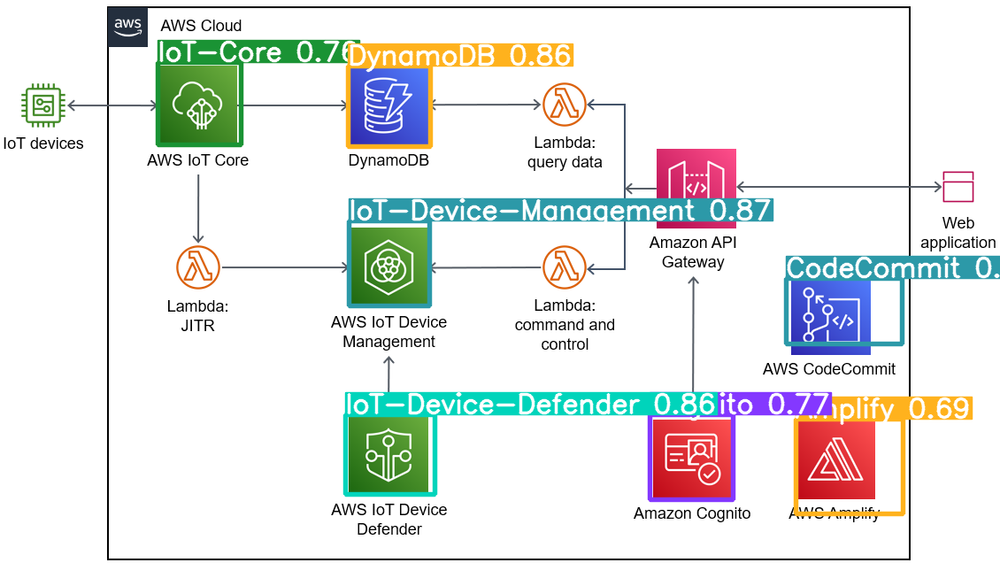
なかなか良さそうです!
良さそう!!!
サーバーレスAPIの作成
作成したモデルを簡単に実行できるよう、API化します。また、使った分だけの利用に抑えるため、Lambdaを使ったサーバーレスなAPIとしました。
まずSAMでプロジェクトを作成します。
sam init
言語はPython、パッケージはコンテナとします。
FROM public.ecr.aws/lambda/python:3.9
COPY requirements.txt best.pt ./
RUN python3.9 -m pip install -r requirements.txt -t .
## Command can be overwritten by providing a different command in the template directly.
CMD ["app.lambda_handler"]
RUN yum install -y mesa-libGL-devel mesa-libGLU-devel libpng-devel
COPY app.py ./
import json
import base64
import numpy as np
import shutil
import cv2
import os
from yolov5 import detect
classes = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 191, 192, 193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220, 221, 222, 223, 224, 225, 226, 227, 228, 229, 230, 231, 232, 233, 234, 235, 236, 237, 238, 239, 240, 241, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254, 255, 256, 257, 258, 259, 260, 261, 262, 263, 264, 265, 266, 267, 268, 269, 270, 271, 272, 273, 274, 275, 276, 277, 278, 279, 280, 281, 282, 283, 284, 285, 286, 287, 288]
def lambda_handler(event, context):
"""Sample pure Lambda function
Parameters
----------
event: dict, required
API Gateway Lambda Proxy Input Format
Event doc: https://docs.aws.amazon.com/apigateway/latest/developerguide/set-up-lambda-proxy-integrations.html#api-gateway-simple-proxy-for-lambda-input-format
context: object, required
Lambda Context runtime methods and attributes
Context doc: https://docs.aws.amazon.com/lambda/latest/dg/python-context-object.html
Returns
------
API Gateway Lambda Proxy Output Format: dict
Return doc: https://docs.aws.amazon.com/apigateway/latest/developerguide/set-up-lambda-proxy-integrations.html
"""
try:
shutil.rmtree('/tmp/input')
except:
pass
try:
shutil.rmtree('/tmp/output')
except:
pass
try:
os.mkdir('/tmp/input')
except:
pass
img_bin = base64.b64decode(event['body'])
img_array = np.frombuffer(img_bin,dtype=np.uint8)
img = cv2.imdecode(img_array, cv2.IMREAD_COLOR)
cv2.imwrite('/tmp/input/target.png',img)
detect.run(
source='/tmp/input/target.png',
weights="best.pt",
project='/tmp',
name='output',
exist_ok=True,
classes=classes
)
with open('/tmp/output/target.png', 'rb') as f:
base64_out = base64.b64encode(f.read()).decode('utf-8')
print(base64_out)
return {
"statusCode": 200,
"headers": { "Content-Type": "image/png" },
"body": base64_out,
"isBase64Encoded": True
}
これで外部から画像を受け取り、AIで推論、推論結果をレスポンスで返却するAPIの完成です。
HTMLからFetch APIを使用して画像をPOSTし、レスポンスをimgタグにセットすれば完成です。
<p style="text-align:center">
<input type="file"><br>
<input type="button" value="送信!" onclick="f1()"><br><br>
<img id="result" src="" style="display:unset">
</p>
<script>
function f1() {
fileField = document.querySelector('input[type="file"]');
fetch('API ENDPOINT', {
method: 'POST',
headers: {
'Content-Type': 'image/png'
},
body: fileField.files[0]
}).then(response => response.blob())
.then(data => {
const img_result = document.getElementById('result');
console.log(img_result)
img_result.src = URL.createObjectURL(data);
console.log(img_result.src)
})
}
</script>
コールドスタート時にモデルのロード処理が走るため、初回のみ時間がかなりかかります。
完成形の紹介
成果から確認いただきましょう。 画像はAWS アーキテクチャーセンターから持ってきました。
テスト①
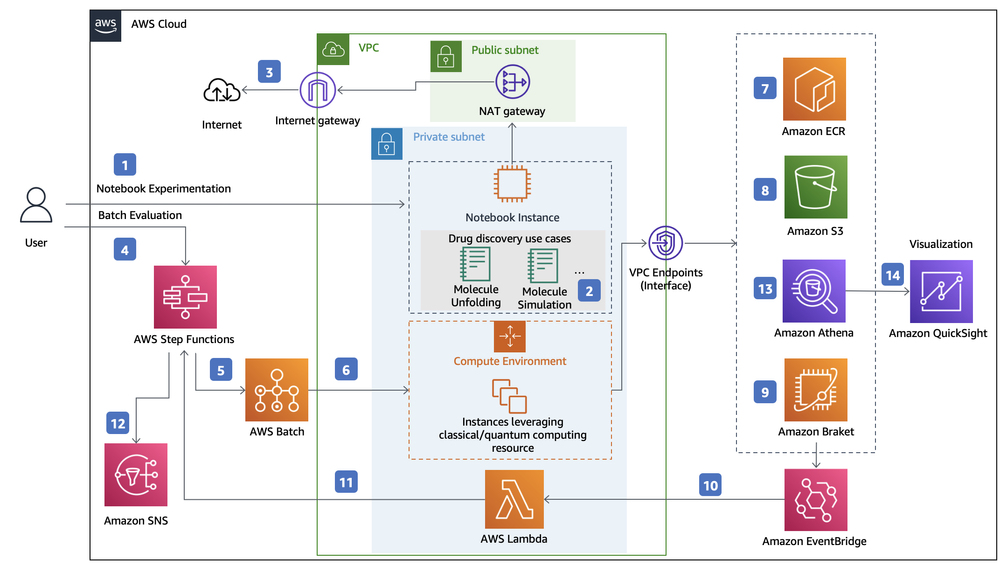
結果
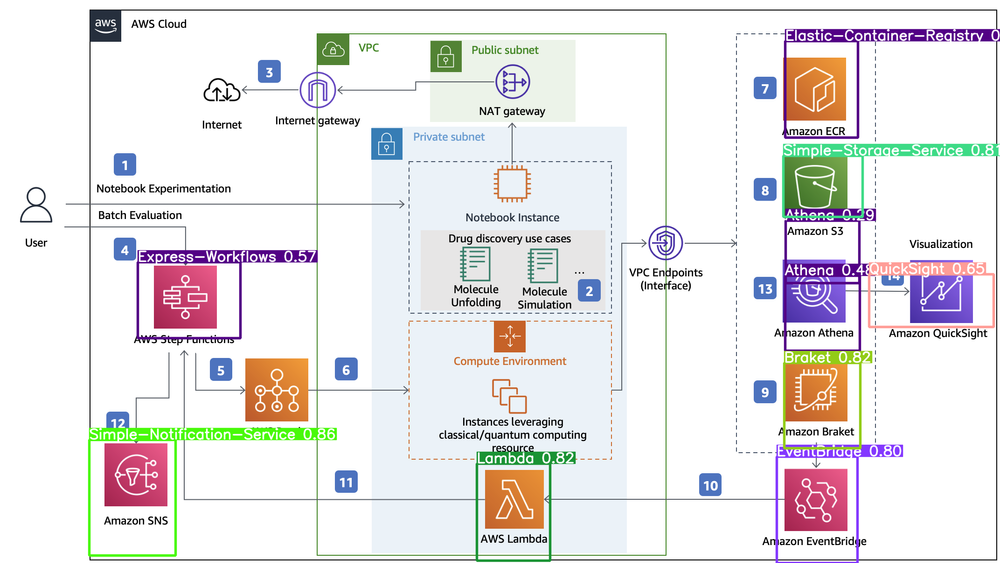
まずまずの結果ではないでしょうか。ほとんどあっているのですが、
- Step FunctionsをExpress Workflowsと誤検出
- Athenaが上下に分かれて2つ検出
- Batchが検出できていない
Step FunctionsとExpress Workflowsなのですが、
| アイコン | サービス名 |
|---|---|
 | Step Functions |
 | Express Workflows |
ほぼ一緒!!!これは同じと捉えても良いのでは!? ということで、ほぼ満点ですね😀
いい感じ!
テスト②
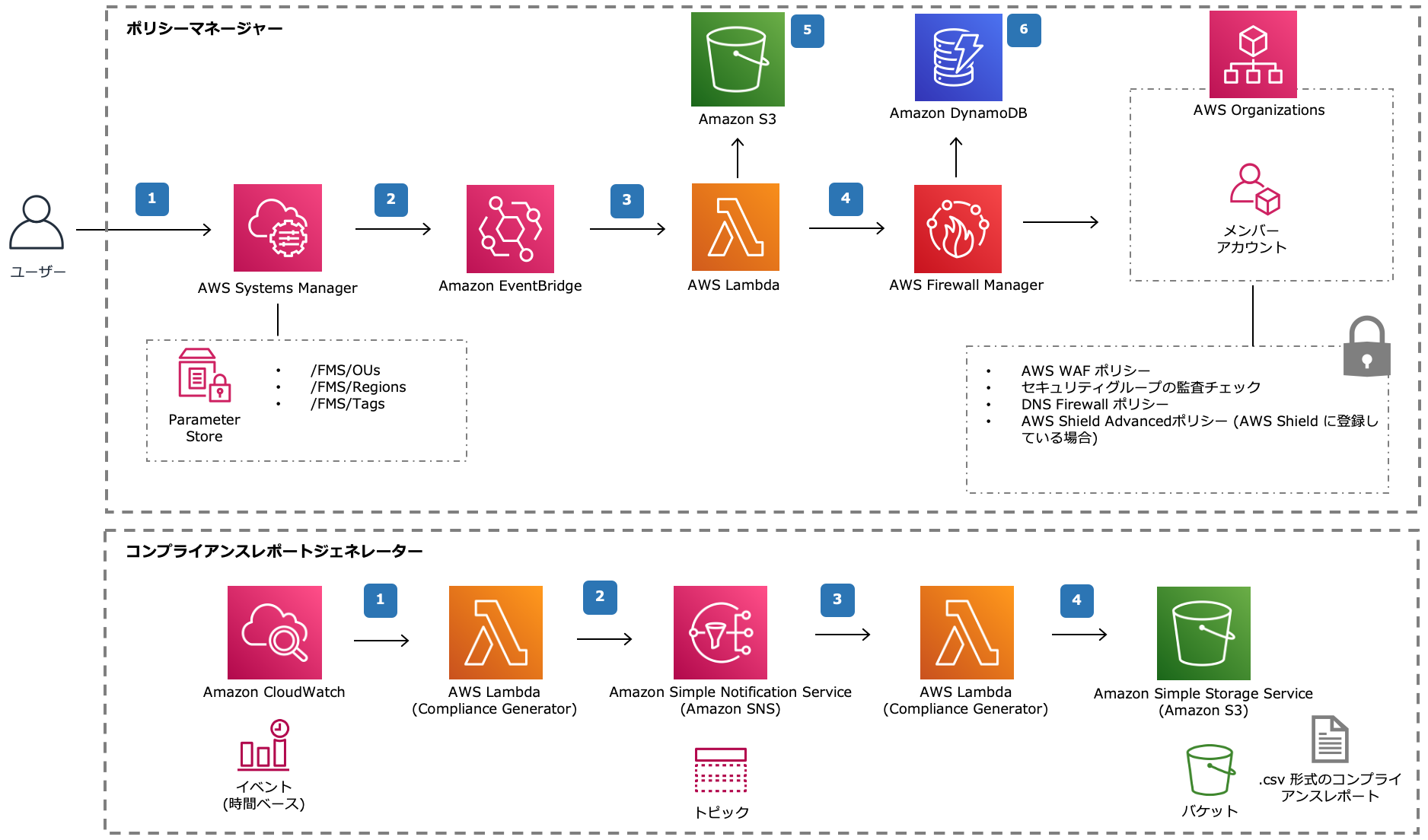
結果
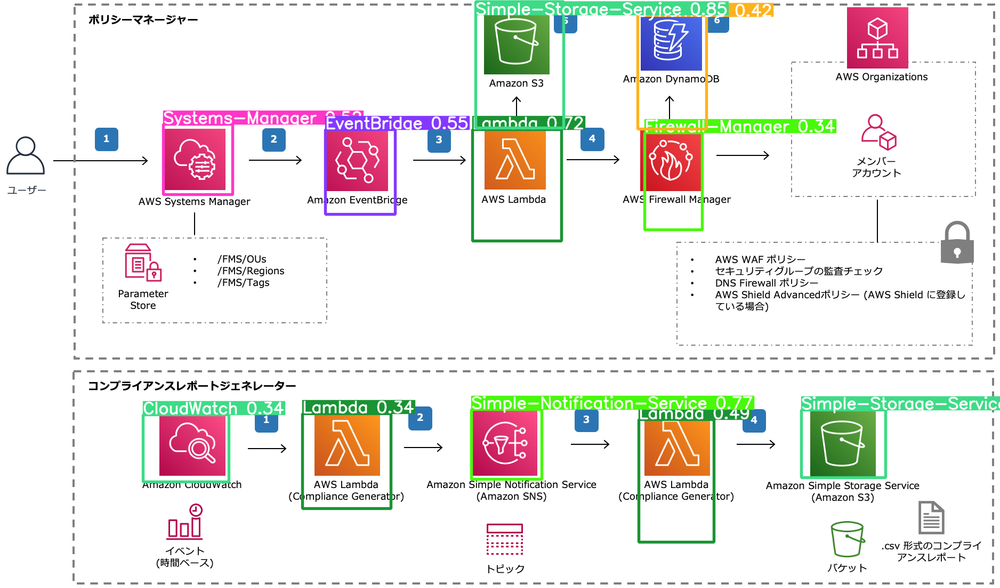
間違いは
- Organizationsが検出できてない
他のものはすべてあってます!!
これもいい感じです
テスト③
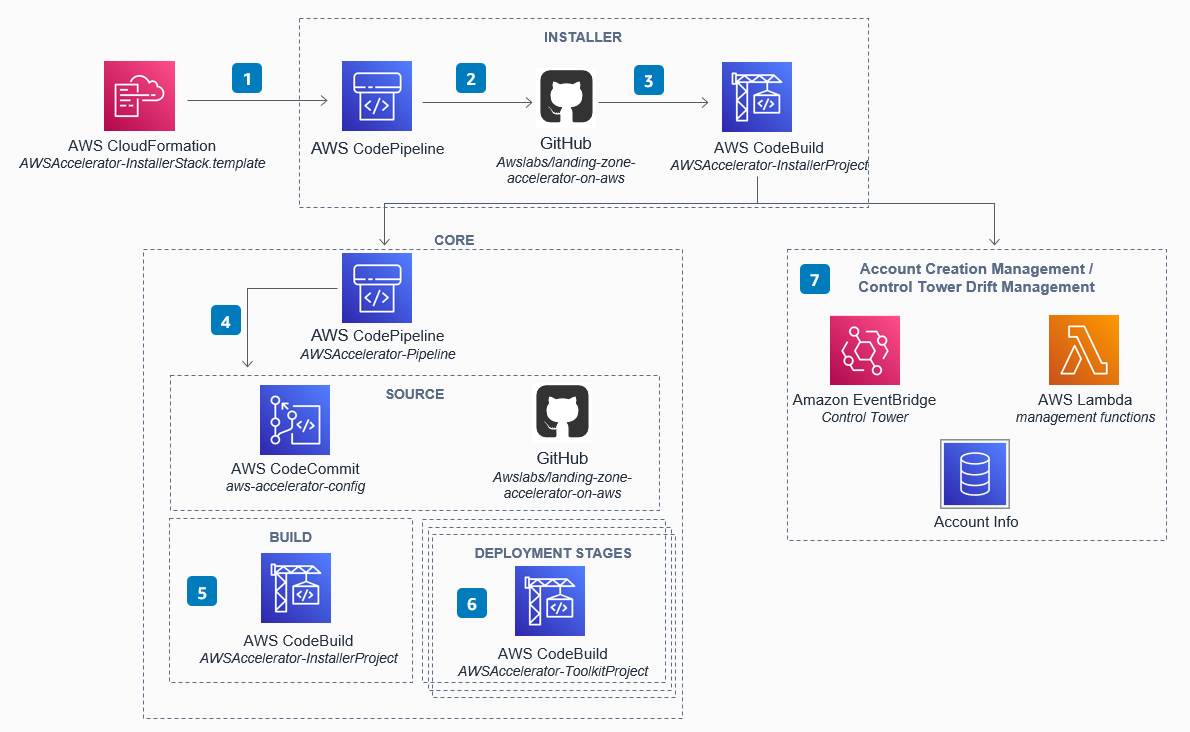
結果
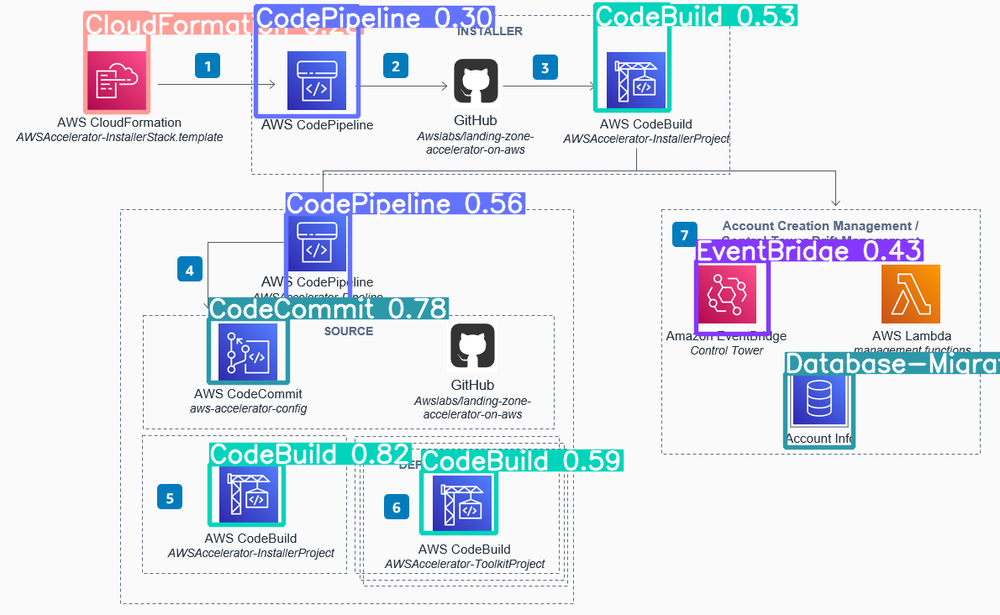
間違いは
- Lambdaが検出できていない
- 右下のデータベースをDatabase Migration Serviceと誤検出
CodeBuildやCodeCommit、CodePipelineを正しく検出できているのは優秀じゃないでしょうか??
ちなみに
| アイコン | サービス名 |
|---|---|
 | Database Migration Service |
いや、 これ正解やん!!
学習したアイコンと違うアイコンが出てくるとご検知します。
テスト④
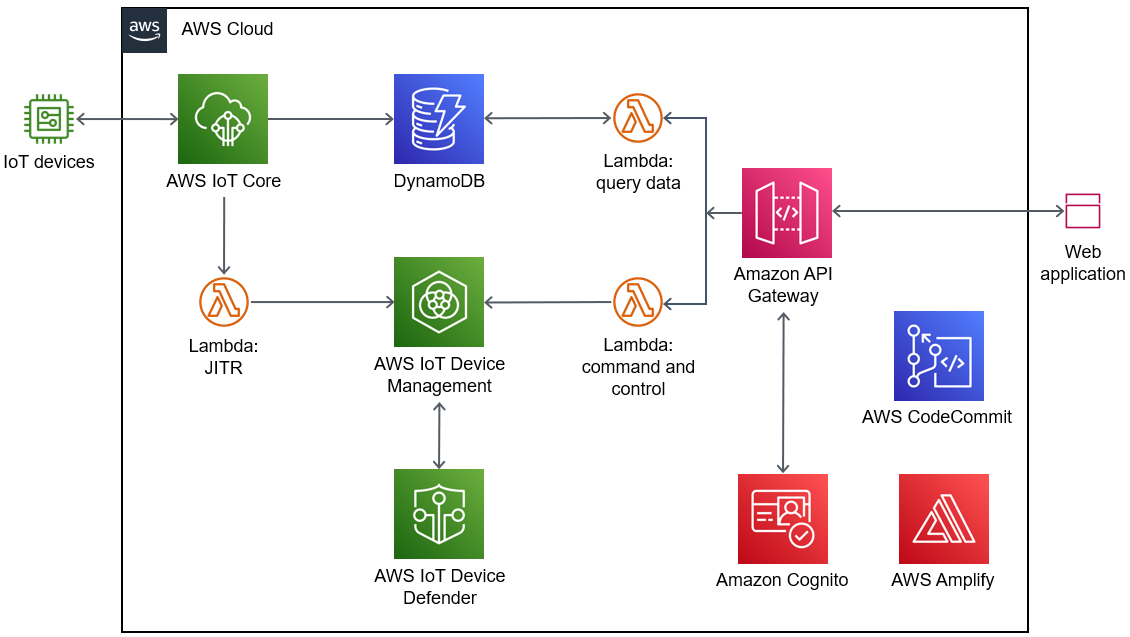
結果
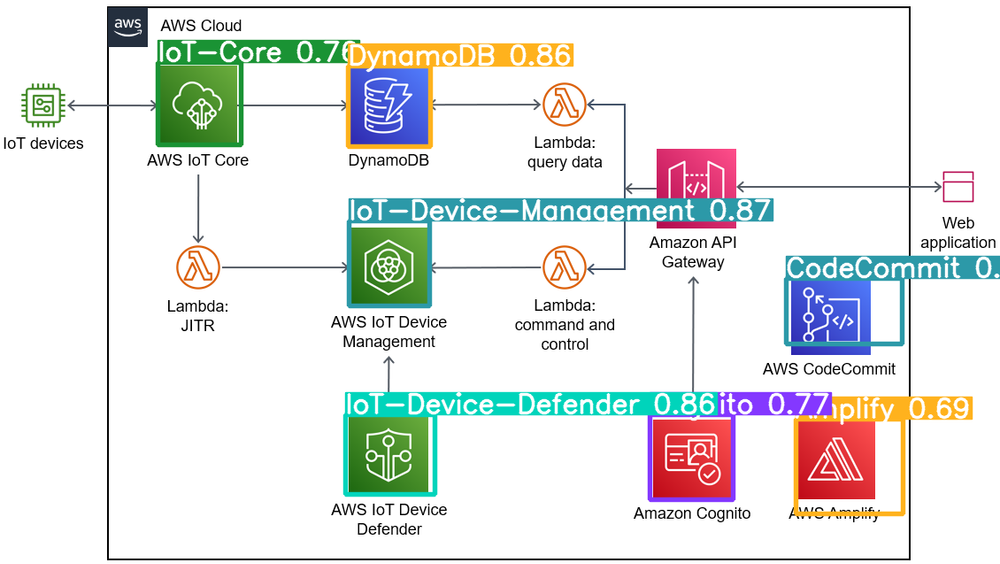
API Gatewayが検出できませんでした。残念!!
API Gatewayはどうしてでしょうね。理由はわかりません。
以上、AWSのアイコンを検知するAIの作成方法でした。