AuroraがBedrockに対応したブログを見て衝撃を受けました。
https://dev.classmethod.jp/articles/amazon-aurora-postgresql-bedrock-ml2/
SELECT aws_bedrock.invoke_model (
'amazon.titan-text-express-v1',
'application/json',
'application/json',
'{"inputText": "what is orange"}'
);
何このSQL www
と思ったのですが、どういうふうに活用するのかいまいちイメージがつかなかったので、実際に検証してみました。
準備
このような環境を構築します。詳細な構築方法はこちらを参照ください。
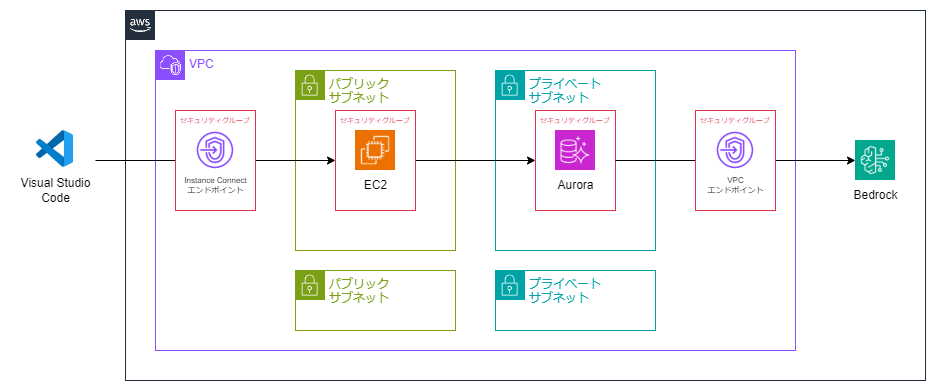
AuroraからBedrockを使用するために必要なのはこのあたりの設定です。
AuroraからBedrockにアクセスするIAMロールを作成する。 手順を参考に実施してください。
Auroraに機械学習拡張をインストールする。 https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/postgresql-ml.html#postgresql-ml-aws_ml-install
CREATE EXTENSION IF NOT EXISTS aws_ml CASCADE;
aws_bedrock.invoke_model
SELECT aws_bedrock.invoke_model (
'amazon.titan-text-express-v1',
'application/json',
'application/json',
'{"inputText": "what is orange"}'
);
{
"inputTextTokenCount": 3,
"results": [
{
"tokenCount": 8,
"outputText": "\nAn orange is a citrus fruit.",
"completionReason": "FINISH"
}
]
}
outputTextの部分だけほしい場合は、
SELECT aws_bedrock.invoke_model (
'amazon.titan-text-express-v1',
'application/json',
'application/json',
'{"inputText": "what is orange"}'
)::json->'results'->0->>'outputText';
\nAn orange is a citrus fruit.
::jsonJSON型に変換
https://www.postgresql.jp/document/13/html/datatype-json.html
-> 'results'、->0->の後ろがtextの場合はJSONのキーを指定してバリューを取得、intの場合は指定した番号の要素を取得
->>'outputText'
指定した要素をtextとして取得
invoke_model_get_embeddings
埋め込みモデルの場合は、invoke_model_get_embeddingsを使用します。
SELECT aws_bedrock.invoke_model_get_embeddings (
'amazon.titan-embed-text-v1',
'application/json',
'embedding',
'{"inputText": "what is orange"}'
);
[0.8984375,0.10058594,0.37695312,0.0055236816,-1.1640625,...]
3つ目のパラメーターのembeddingは、invoke_modelで実行した際のレスポンスで、ベクトル配列が格納されているキーです。
{
"embedding": [0.8984375,0.10058594,0.37695312, ...], <--このキー
"inputTextTokenCount": 3
}
なので、Cohere Embedの場合はembeddingsになると思います。
ベクトルデータベースを作成
ベクトル化した値をデータベースに格納します。
テーブルの形式はKnowledge Base for Amazon Bedrockのスキーマと合わせてみました。
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraPostgreSQL.VectorDB.html
Knowledge Base for Amazon BedrockではData APIが必須ですが、今回の検証では不要です。
上記サイトに従いテーブルを作成します。
CREATE EXTENSION IF NOT EXISTS vector;
CREATE SCHEMA bedrock_integration;
CREATE TABLE bedrock_integration.bedrock_kb (
id uuid PRIMARY KEY,
embedding vector(1536),
chunks text,
metadata json
);
CREATE INDEX on bedrock_integration.bedrock_kb USING hnsw (embedding vector_cosine_ops);
ベクトル化したデータを登録します。
INSERT INTO bedrock_integration.bedrock_kb (id, embedding, chunks, metadata)
VALUES (
gen_random_uuid(),
CAST(
aws_bedrock.invoke_model_get_embeddings (
'amazon.titan-embed-text-v1',
'application/json',
'embedding',
'{"inputText": "what is orange"}'
) as vector
),
'what is orange',
'{"outputText": "An orange is a citrus fruit."}'
);
metadataは好きなJSONが登録できます。質問に対する回答を入れてみました。
登録できたので検索してみましょう。
SELECT *
FROM bedrock_integration.bedrock_kb
ORDER BY embedding <->CAST(
aws_bedrock.invoke_model_get_embeddings (
'amazon.titan-embed-text-v1',
'application/json',
'embedding',
'{"inputText": "what is orange"}'
) AS vector
)
LIMIT 5;
<->でベクトル同士の近さが取得できます。他に<#>や<=>もサポートされているようです。近い順に並び替えて上位5件を取得しています。
https://github.com/pgvector/pgvector
Aurora単体でRAG
ここまで来たらRAG化したくなりました。SQLが長くなってきました。
サンプルとして、以下2件のデータを登録しました。
| Question | Answer |
|---|---|
| Q: What is Amazon Elastic Compute Cloud (Amazon EC2)? | Amazon EC2 is a web service that provides resizable compute capacity in the cloud. It is designed to make web-scale computing easier for developers. |
| What is Amazon S3? | Amazon S3 is object storage built to store and retrieve any amount of data from anywhere. S3 is a simple storage service that offers industry leading durability, availability, performance, security, and virtually unlimited scalability at very low costs. |
INSERT文はこちら
INSERT INTO bedrock_integration.bedrock_kb (id, embedding, chunks, metadata)
VALUES (
gen_random_uuid(),
CAST(
aws_bedrock.invoke_model_get_embeddings (
'amazon.titan-embed-text-v1',
'application/json',
'embedding',
'{"inputText": "Q: What is Amazon Elastic Compute Cloud (Amazon EC2)?"}'
) as vector
),
'Q: What is Amazon Elastic Compute Cloud (Amazon EC2)?',
'{"outputText": "Amazon EC2 is a web service that provides resizable compute capacity in the cloud. It is designed to make web-scale computing easier for developers."}'
),
(
gen_random_uuid(),
CAST(
aws_bedrock.invoke_model_get_embeddings (
'amazon.titan-embed-text-v1',
'application/json',
'embedding',
'{"inputText": "What is Amazon S3?"}'
) as vector
),
'What is Amazon S3?',
'{"outputText": "Amazon S3 is object storage built to store and retrieve any amount of data from anywhere. S3 is a simple storage service that offers industry leading durability, availability, performance, security, and virtually unlimited scalability at very low costs."}'
);
プロンプトはこちらを参考に以下の文としました。
Human:
Use the provided articles to answer questions. If the answer cannot be found in the articles, write \"I could not find an answer.\"
${KNOWLEDGE} Question: ${QUESTION}
Assistant:
${KNOWLEDGE}と${QUESTION}はSQLの中で置換します。
Claude Instantを使用して、上位2件の結果を元にサマライズします。
SELECT aws_bedrock.invoke_model (
'anthropic.claude-instant-v1',
'application/json',
'application/json',
T4.PROMPT
)::json->'completion' as A,
Q,
PROMPT
FROM (
SELECT REPLACE(
REPLACE(
'{"prompt": "Human:\n\nUse the provided articles to answer questions. If the answer cannot be found in the articles, write \"I could not find an answer.\"\n\n<knowledge>${KNOWLEDGE}</knowledge>\n\nQuestion: ${QUESTION} \n\nAssistant:", "max_tokens_to_sample": 300}',
'${KNOWLEDGE}',
T3.outputText
),
'${QUESTION}',
Q
) as PROMPT,
Q
FROM (
SELECT STRING_AGG(T2.outputText, '\n\n') as outputText,
Q
FROM (
SELECT metadata->>'outputText' as outputText,
Q
FROM bedrock_integration.bedrock_kb,
(
SELECT 'What is EC2?' as Q
) T1
ORDER BY embedding <->CAST(
aws_bedrock.invoke_model_get_embeddings (
'amazon.titan-embed-text-v1',
'application/json',
'embedding',
REPLACE(
'{"inputText": "${QUESTION}"}',
'${QUESTION}',
Q
)
) AS vector
)
LIMIT 2
) T2
GROUP BY Q
) T3
) T4
{""prompt"": ""Human:\n\nUse the provided articles to answer questions. If the answer cannot be found in the articles, write \""I could not find an answer.\""\n\n<knowledge>Amazon EC2 is a web service that provides resizable compute capacity in the cloud. It is designed to make web-scale computing easier for developers.\n\nAmazon S3 is object storage built to store and retrieve any amount of data from anywhere. S3 is a simple storage service that offers industry leading durability, availability, performance, security, and virtually unlimited scalability at very low costs.</knowledge>\n\nQuestion: What is EC2? \n\nAssistant:"", ""max_tokens_to_sample"": 300}
What is EC2?
Amazon EC2 is a web service that provides resizable compute capacity in the cloud. It is designed to make web-scale computing easier for developers.
うまくいきました!!
まとめ
Aurora Postgresのベクトルデータベース化とBedrock呼び出しを試しました。単体でのRAG化もできました。ベクトル化や検索をデータベース側にオフロードできますね。