生成AIではモデルにより文字列のベクトル化が行えます。 Amazon Bedrockでは、「Titan Embeddings」というモデルが提供されています。 Titan Embeddingsのユースケースのひとつに semantic similarity(意味的類似度) というものがあります。
意味の近い言葉は、近くに来るよということだと思います。
この機能を使って、re:Invent 2023のセッションを可視化してみました。
データの取得
Chromeのデベロッパーツールを開いた状態でこちらのサイトにアクセスます。
public-catalog/へのアクセスを探し、右クリック → Copy → Copy as cURL でコマンドをコピーします。コピーしたコマンドを、Bashで実行し、JSONファイルを保存します。
データのベクトル化
ライブラリーの取得
pip install -Uq pandas python-dotenv boto3
pip install -Uq scikit-learn matplotlibimportとベクトル化関数の定義
import json
import boto3
from dotenv import load_dotenv
load_dotenv(override=True)
bedrock = boto3.client('bedrock-runtime')
def embeddings(input: str):
params = {
'modelId': 'amazon.titan-embed-text-v1',
'contentType': 'application/json',
'accept': '*/*',
'body': json.dumps({
'inputText': input
})
}
response = bedrock.invoke_model(**params)
return json.loads(response['body'].read().decode('utf-8'))['embedding']JSONファイルの読み込み
import pandas as pd
with open('./public-catalog.json') as f:
catalog = json.load(f)
df = pd.read_json(json.dumps(catalog['data']))df['description']に、各セッションの詳細説明が入ってますので、これをベクトル化し、embedding列に追加します。def description(input):
return json.dumps(embeddings(input))
df['embedding'] = df['description'].apply(description)ベクトルーデータの位置を算出
openai-cookbookのVisualizing the embeddings in 2Dを参考にしました。
import pandas as pd
from sklearn.manifold import TSNE
import numpy as np
from ast import literal_eval
# Convert to a list of lists of floats
matrix = np.array(df.embedding.apply(literal_eval).to_list())
# Create a t-SNE model and transform the data
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init='random', learning_rate=200)
vis_dims = tsne.fit_transform(matrix)
x = [x for x,y in vis_dims]
y = [y for x,y in vis_dims]
df['x'] = x
df['y'] = yタグ情報を変換
tagsの中にTopicやArea of Interestが含まれているのですが、扱いづらいので少し整形しました。def tags_transform(input):
topic = list(filter(lambda x: x['parentTagName'] == 'Topic', input))
topic = list(map(lambda x: x['tagName'], topic))
area_of_interest = list(filter(lambda x: x['parentTagName'] == 'Area of Interest', input))
area_of_interest = list(map(lambda x: x['tagName'], area_of_interest))
return {
'topic': topic,
'Area of Interest': area_of_interest
}
df['tags_v2'] = df['tags'].apply(tags_transform)CSVファイルに保存
df.to_csv('all_with_xy.csv')
可視化
できたCSVファイルをPowerBIで可視化しました。
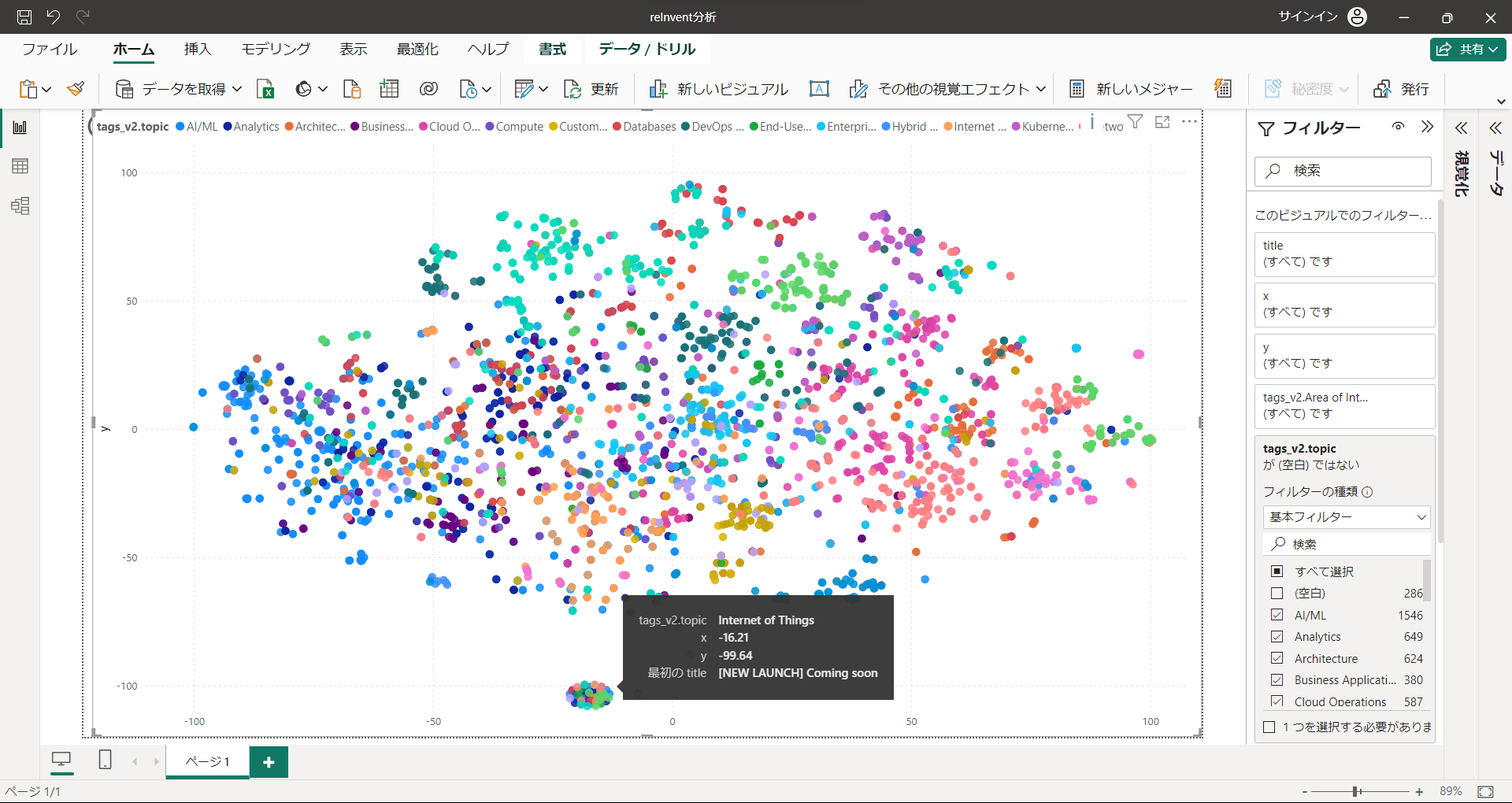
全体
ドーン と。
Topic(AI/ML、Computeなど)で色分けしています。なんとなく、傾向がありそうです。
詳細
トピックごとに分けて見てみましょう。
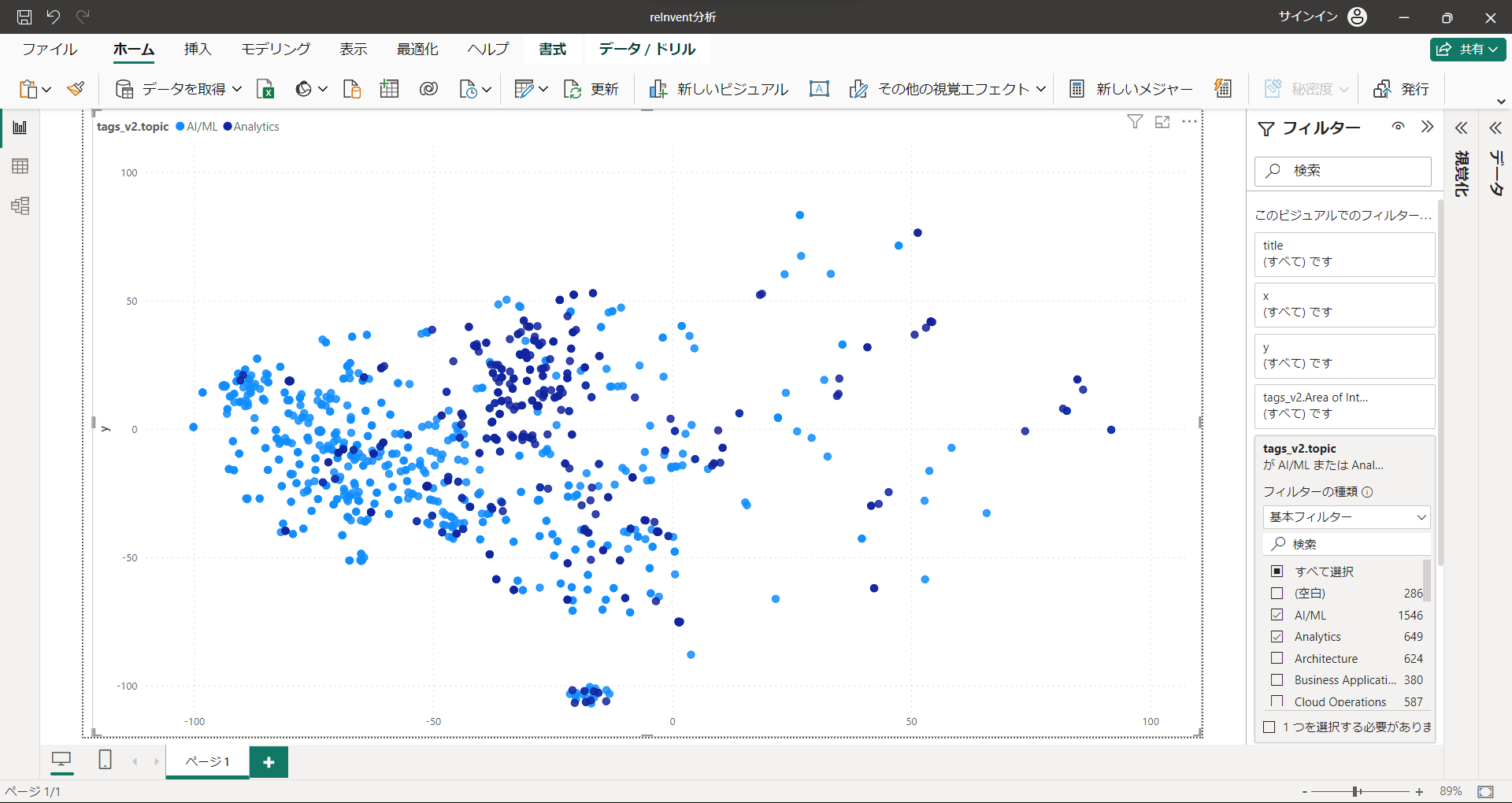
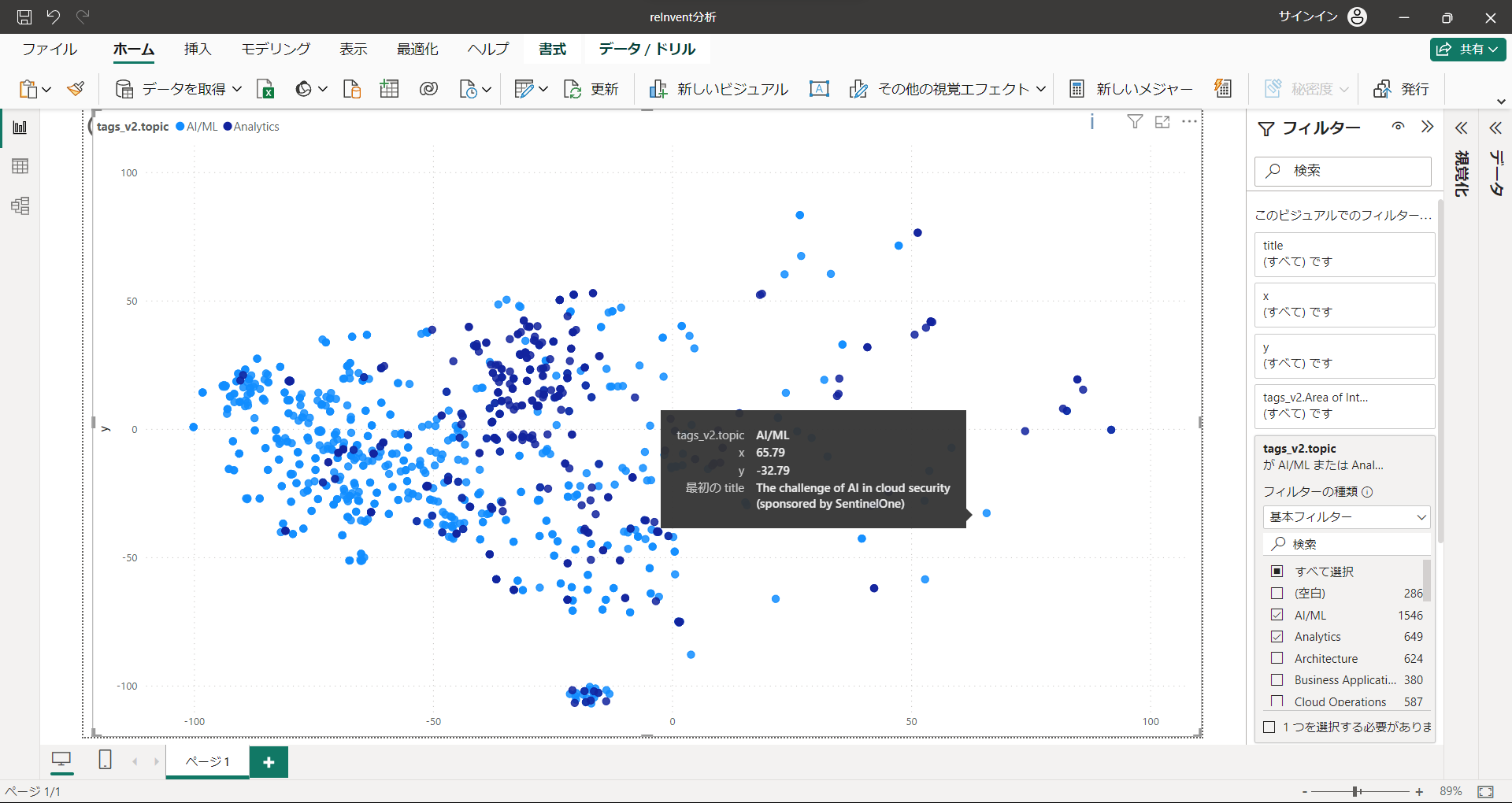
"AI/ML", "Analytics"
最もセッション数の多い2トップです。左側エリアをほぼ占拠しています。
"Networking & Content Delivary", "Storage"
対して右側エリアに集中しているのがこちら。
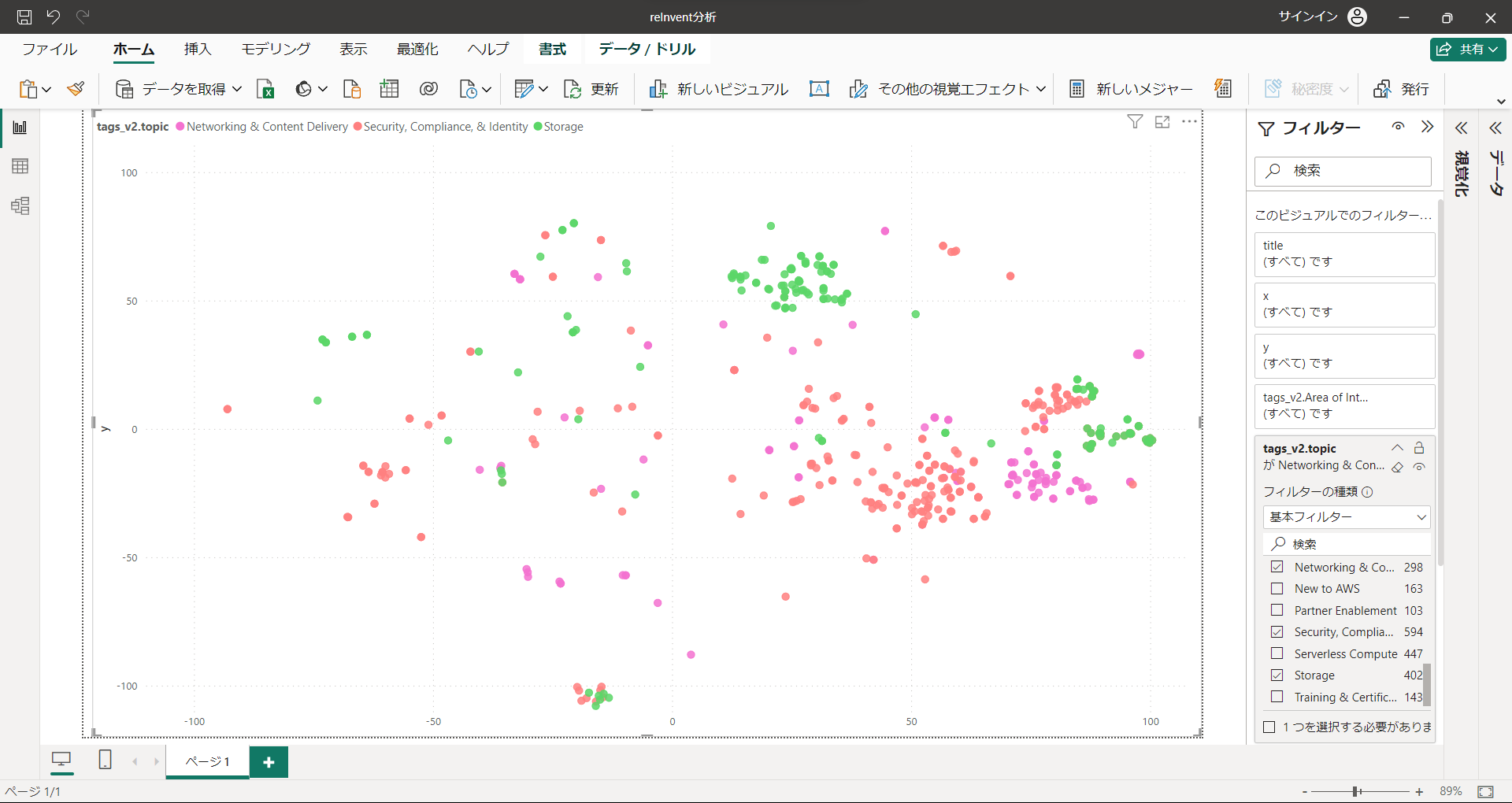
左のAI/MLエリアに位置するセキュリティのセッションはこちら
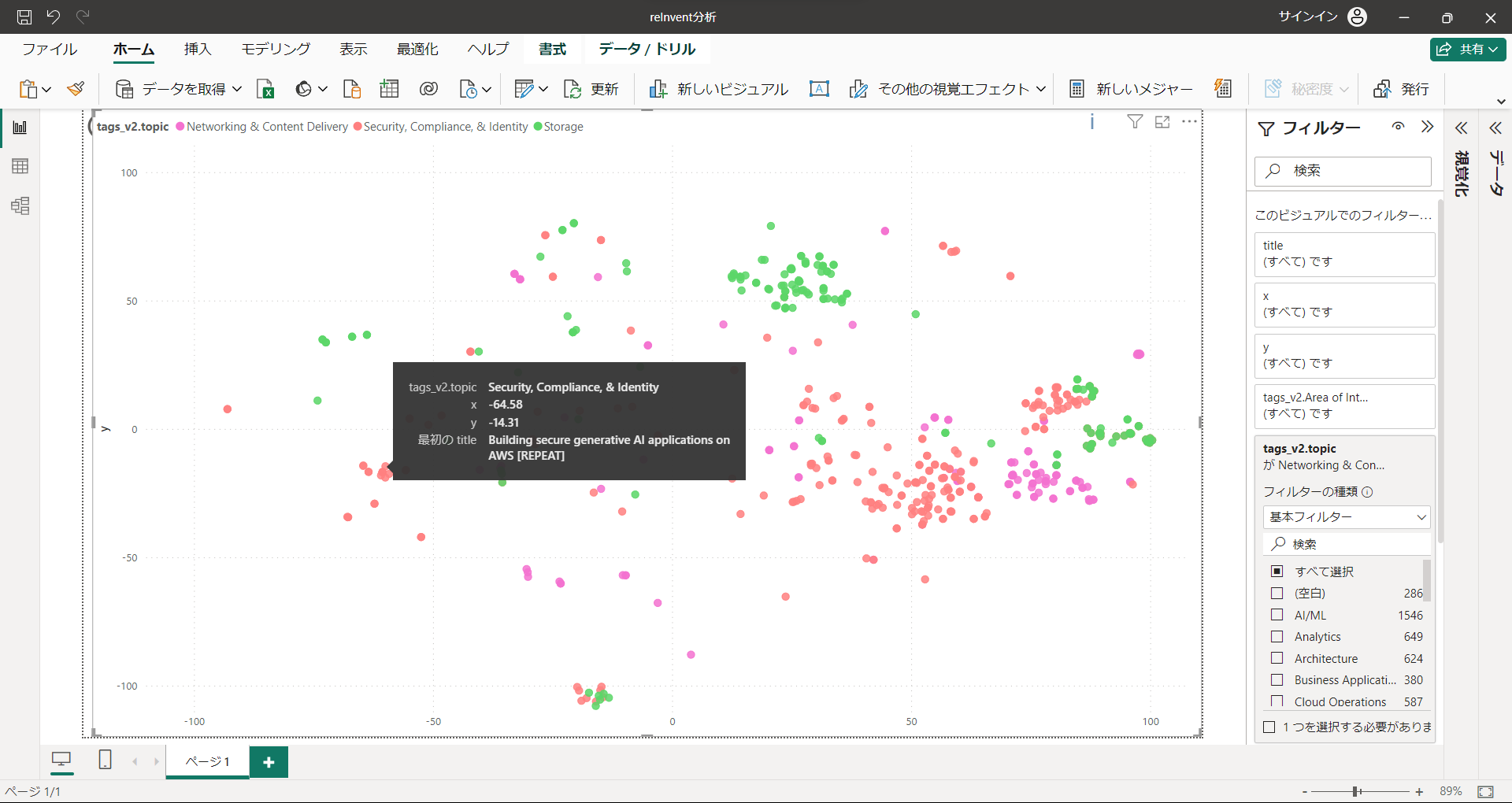
確かにAI要素がありつつ、セキュリティに関するセッションのようです。
ただ、AI/MIのジャンルで右側に来るものもあるので、このあたりはどういう違いがあるんでしょうね。。
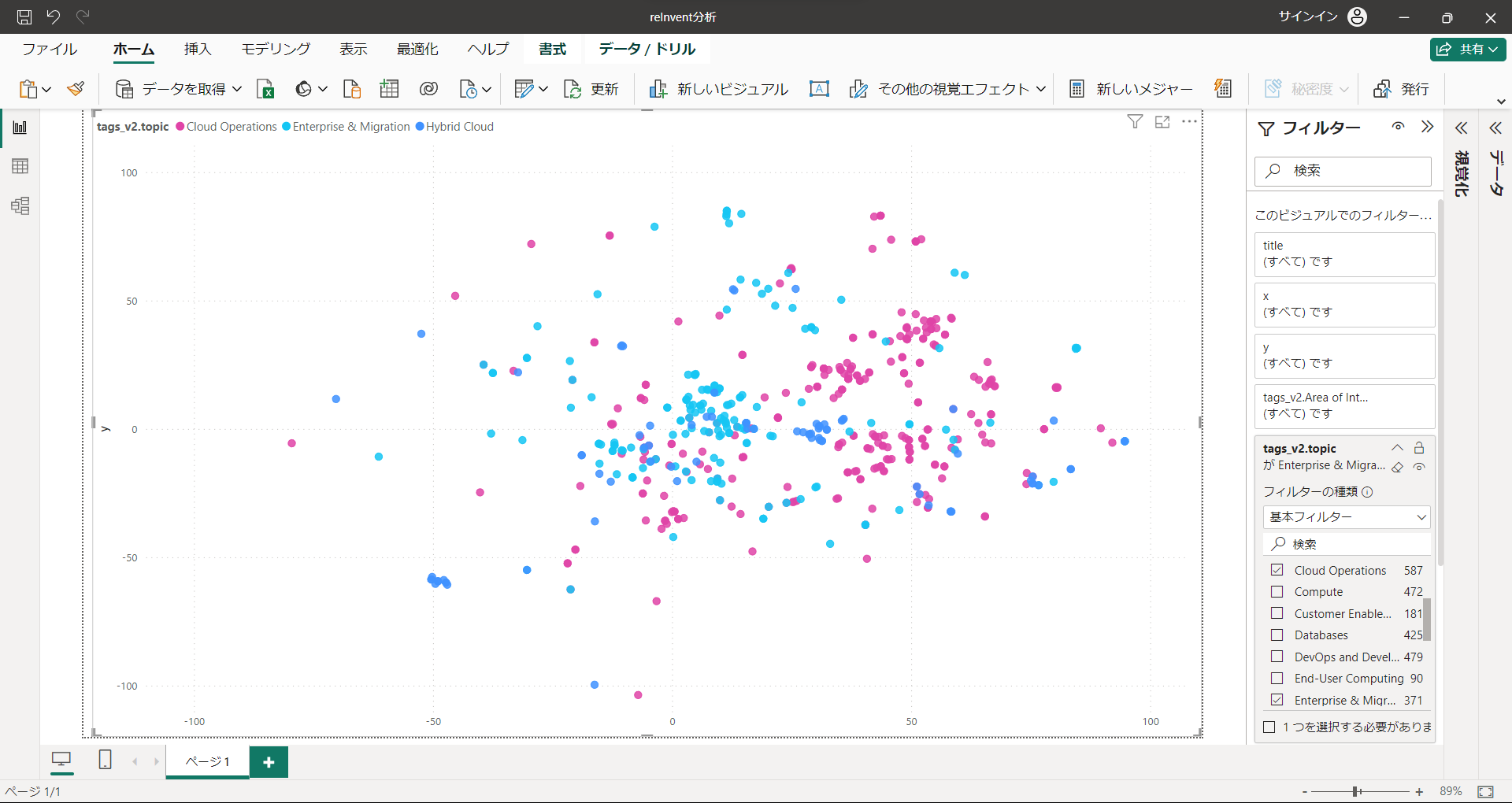
"Cloud Operations", "Enterprise & Migration", "Hybrid Cloud"
真ん中あたりはこちら。テーマ的にも近そうだなと感じました。
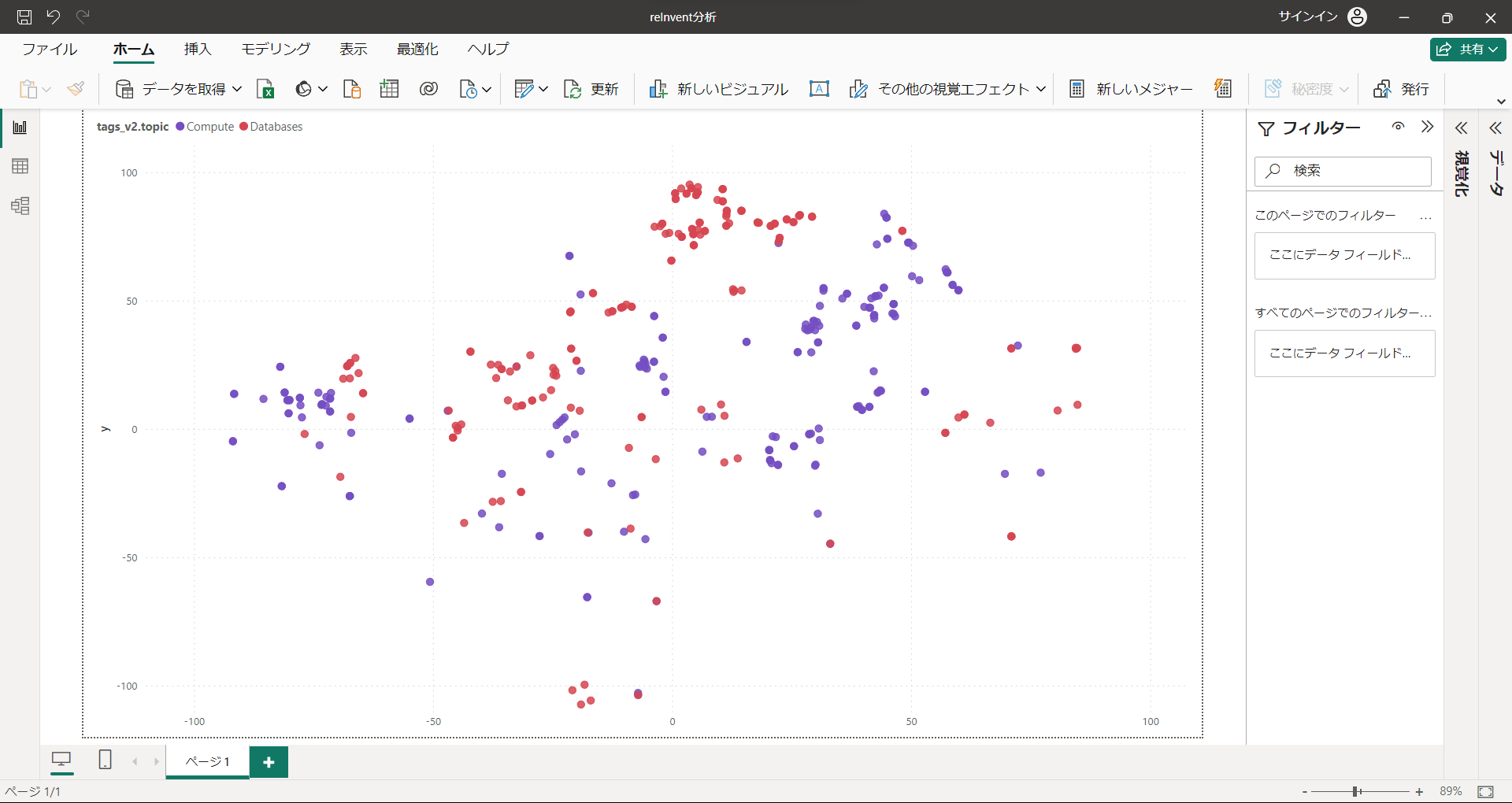
Compute, Database
基本的なサービスのコンピュートとデータベースは幅広く分布している印象です。
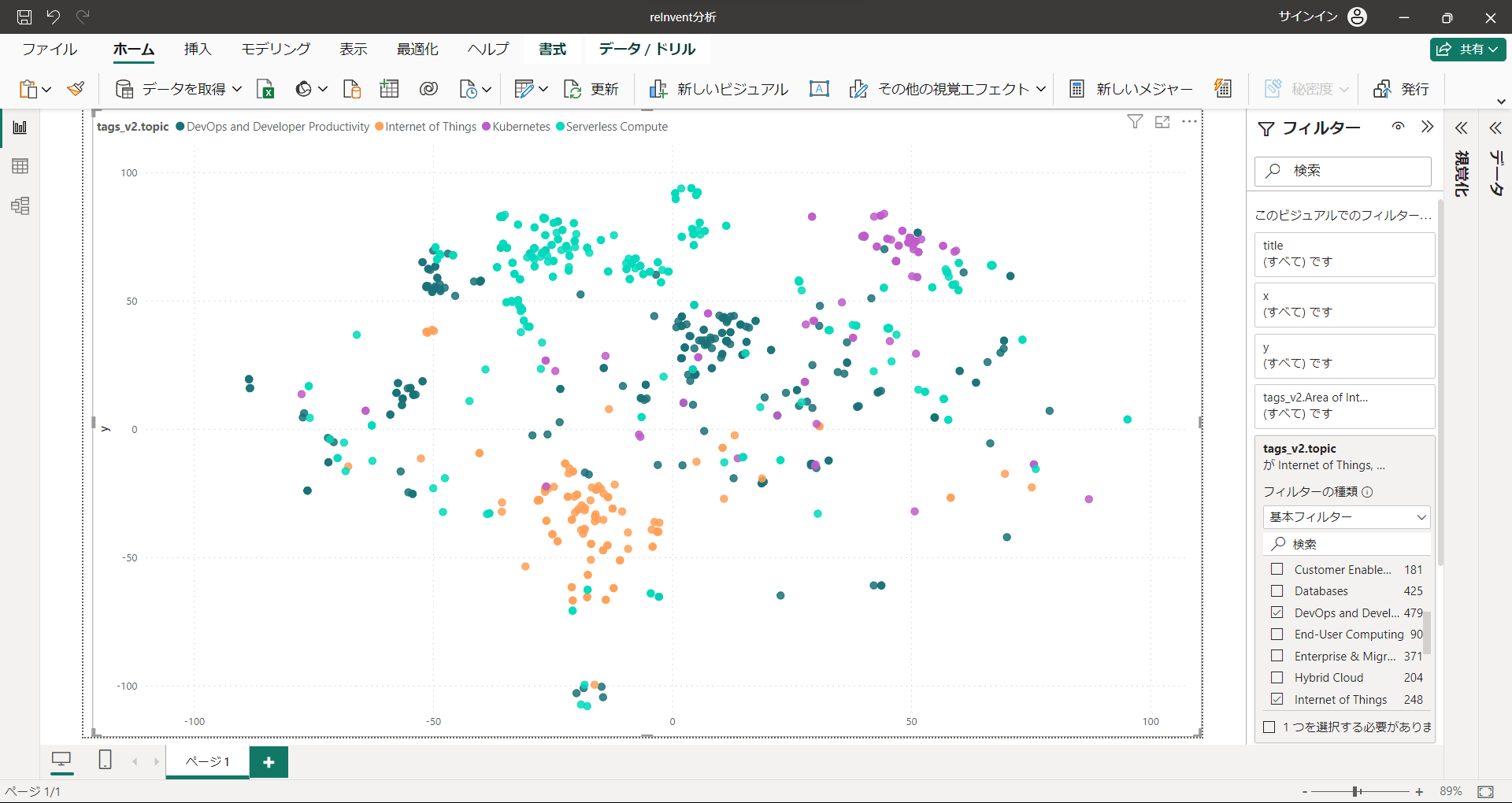
"DevOps and Developer Productivity", "Internet of Things", "Kubernetes", "Serverless Compute"
周辺に位置するのがこれらのテーマ。
気づいたこと
この散布図から見たいセッションを探すのもありのような気がします。
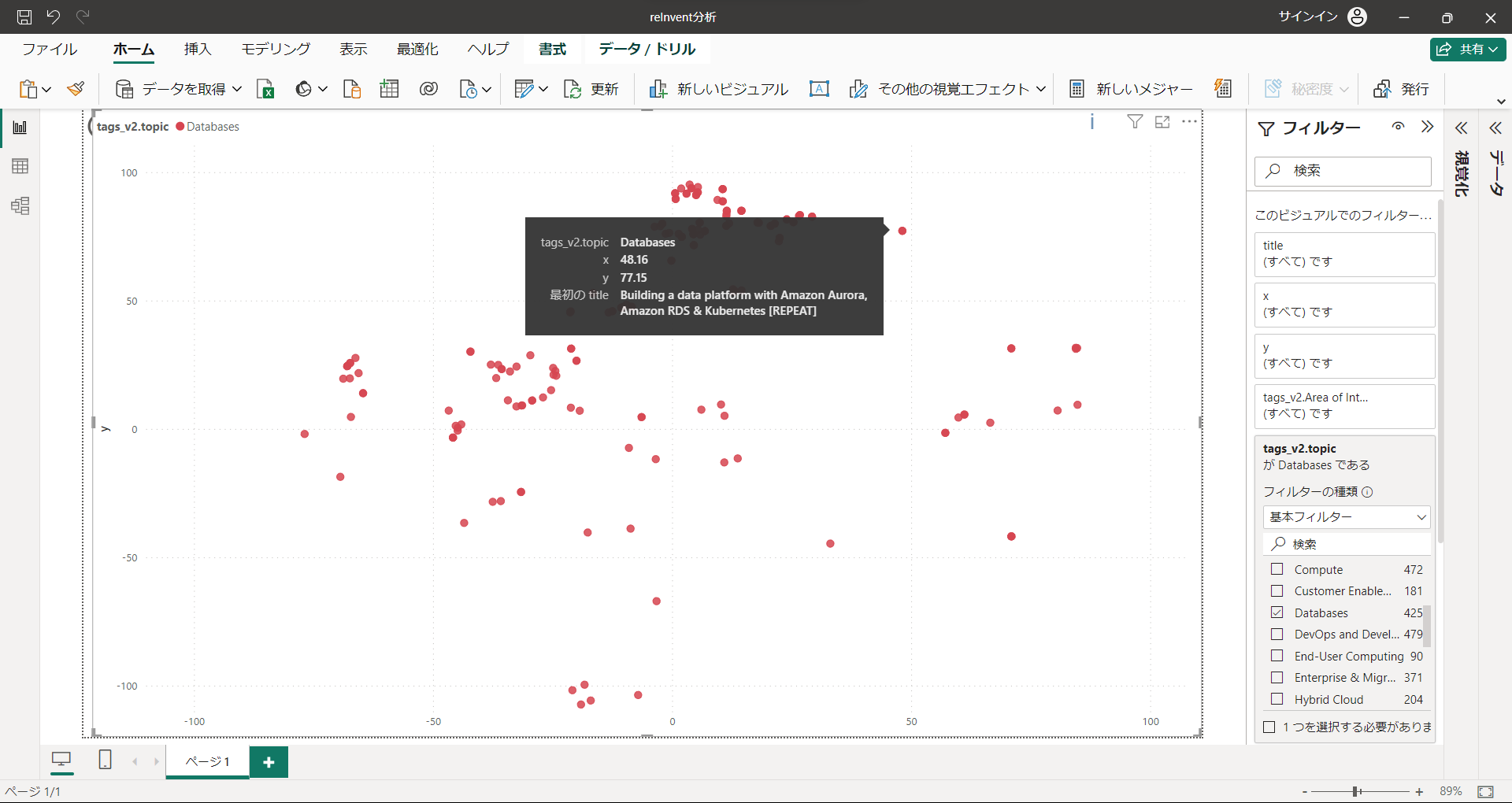
データベースに関するセッションで、Kubernetes寄りのもの
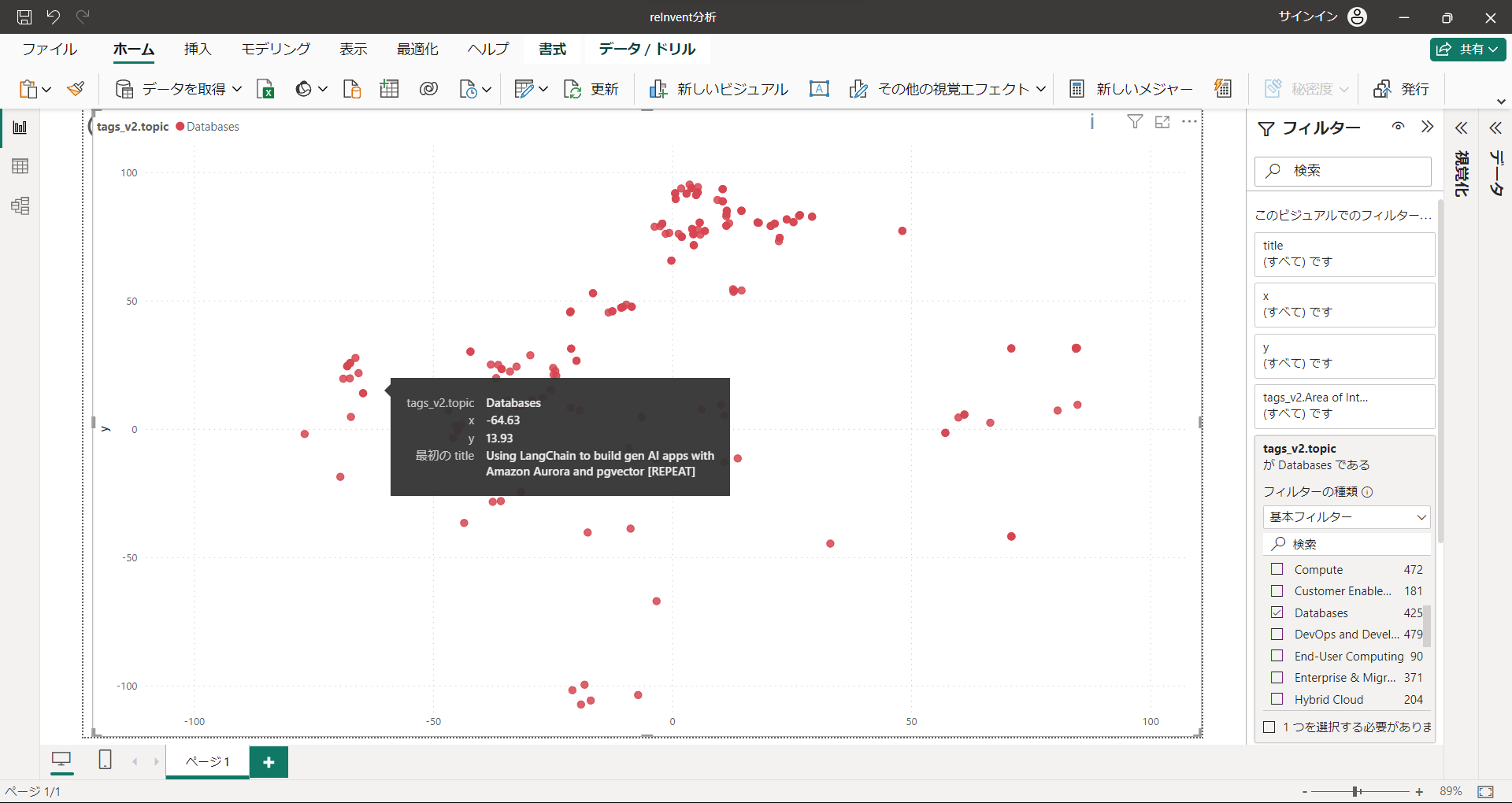
同じくデータベースに関するセッションで、AI/ML寄りのもの
データベースのマイグレーション
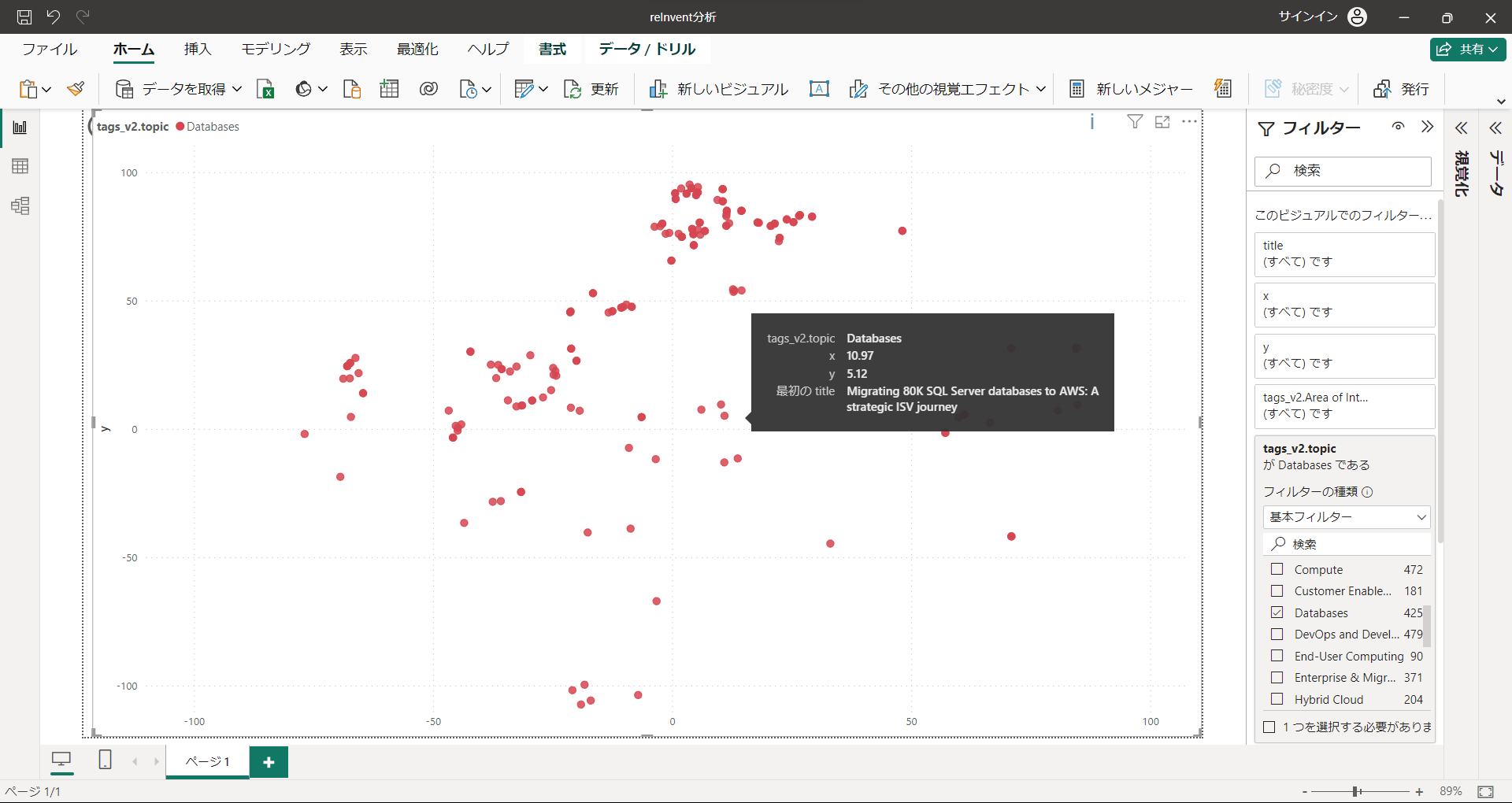
散布図を見ながら、左寄りのセッションいっぱい予約したんで、ひとつぐらい右側で探そうか 的なこともできそうです。
各Topicごとの図
こちらを参照ください。
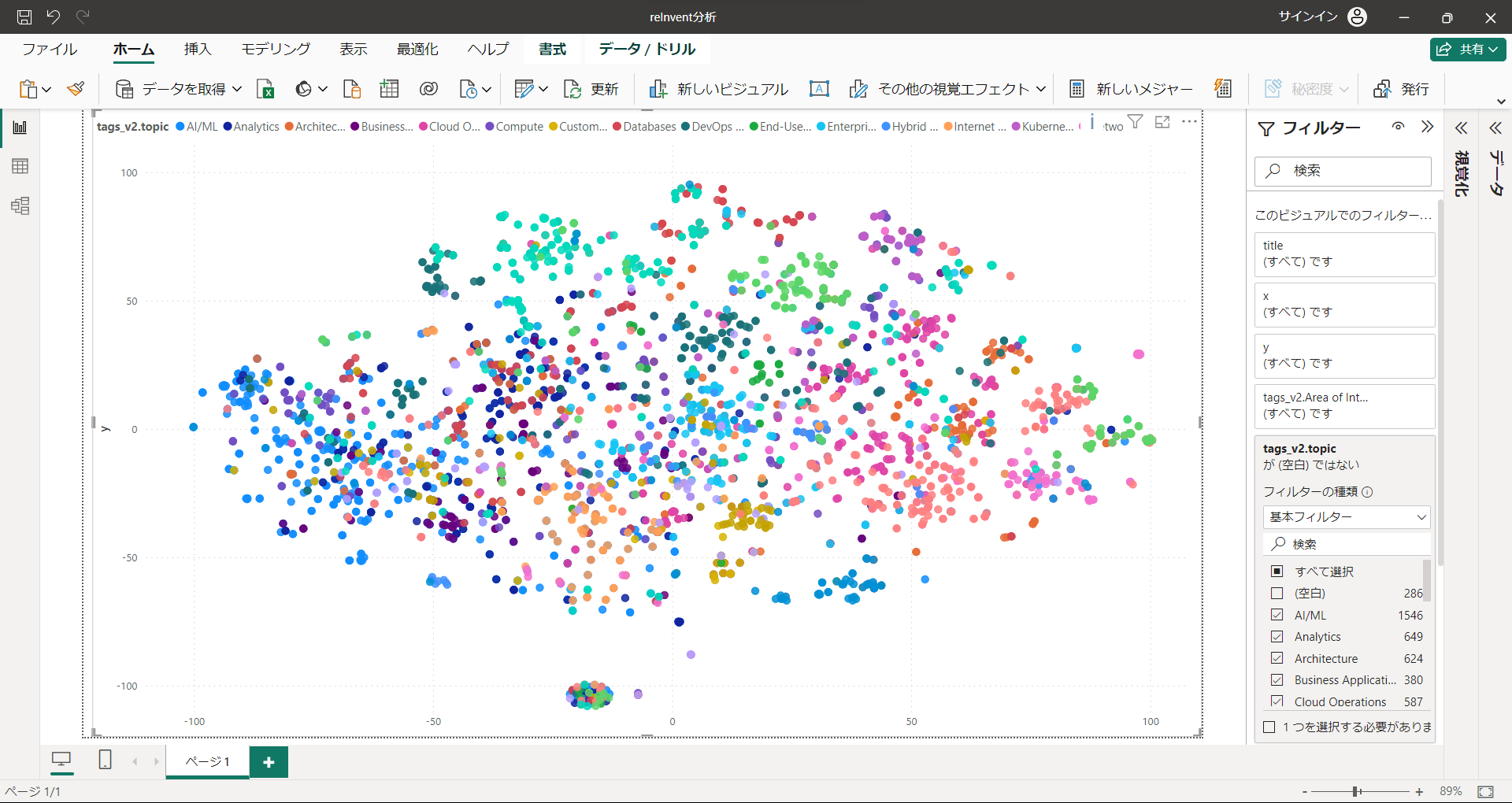
ちなみに下の真ん中あたりに集中したエリアは"New Launch"のセッションです。どんなセッションが増えるのか楽しみですね。